

meet your new data lakehouse: S3 Iceberg Tables
S3 Tables and S3 Metadata are two new features that compete with common Apache Iceberg Lakehouse architectures


Reading time: 13 minutes.
tl;dr
S3 Tables is a new S3 Bucket Type, where anything you write via the S3 API gets translated into Parquet files and organized under the Iceberg open table format.
It offers additional functionality in maintaining/optimizing the tables, and in regular Iceberg fashion - is expected to be open to use from many query engines.
It is around 37% more expensive than S3 Standard.
S3 Metadata is a new automagic way to store metadata of any S3 bucket’s objects.
Once enabled, the system automatically stores and maintains (!) the metadata in a S3 Table (Iceberg table), in near real time.
This allows you to more-easily leverage modern query engines to analyze/visualize/process your data lake’s metadata.
Talk about Iceberg Catalogs, the open table format war and project neutrality

Stan: Hey! Welcome to the first edition of Big Data Stream! I’m excited to get this newsletter going.
Today, we will be diving into the seemingly-endless topic of Apache Iceberg and by extension - S3.
S3 announced two major features this past re:Invent.
S3 Tables
S3 Metadata
Let’s dive into it.
S3 Tables

This is first-class Apache Iceberg support in S3.
You use the S3 API, and behind the scenes it stores your data into Parquet files under the Iceberg table format. That’s it.
It’s an S3 Bucket type, of which there were only 2 previously:
S3 General Purpose Bucket - the usual, replicated S3 buckets we are all used to
S3 Directory Buckets - these are single-zone buckets (non-replicated).
They also have a hierarchical structure (file-system directory-like) as opposed to the usual flat structure we’re used to.
They were released alongside the Single Zone Express low-latency storage class in 2023
new: S3 Tables (2024)
AWS is clearly trending toward releasing more specialized bucket types.
✨ Features
The “managed Iceberg service” acts a lot like an Iceberg catalog:
single source of truth for metadata
automated table maintenance via:
compaction - combines small table objects into larger ones
snapshot management - first expires, then later deletes old table snapshots
unreferenced file removal - deletes stale objects that are orphaned
table-level RBAC via AWS’ existing IAM policies
single source of truth and place of enforcement for security (access controls, etc)
While these sound somewhat basic, they are all very useful.
🔥 Perf
AWS is quoting massive performance advantages:
3x faster query performance
10x more transactions per second (tps)
This is quoted in comparison to you rolling out Iceberg tables in S3 yourself.
I haven’t tested this personally, but it sounds possible if the underlying hardware is optimized for it.
If true, this gives AWS a very structural advantage that’s impossible to beat - so vendors will be forced to build on top of it.
What Does it Work With?
Out of the box, it works with open source Apache Spark.
And with proprietary AWS services (Athena, Redshift, EMR, etc.) via a few-clicks AWS Glue integration.
There is this very nice demo from Roy Hasson on LinkedIn that goes through the process of working with S3 Tables through Spark. It basically integrates directly with Spark so that you run `CREATE TABLE` in the system of choice, and an underlying S3 Tables bucket gets created under the hood.
💸 Cost
The pricing is quite complex, as usual. You roughly have 4 costs:
Storage Costs - these are 15% higher than Standard S3.
They’re also in 3 tiers (first 50TB, next 450TB, over 500TB each month)
S3 Standard: $0.023 / $0.022 / $0.021 per GiB
S3 Tables: $0.0265 / $0.0253 / $0.0242 per GiB
PUT and GET request costs - the same $0.005 per 1000 PUT and $0.0004 per 1000 GET
Monitoring - a necessary cost for tables, $0.025 per 1000 objects a month.
this is the same as S3 Intelligent Tiering’s Archive Access monitoring cost
Compaction - a completely new Tables-only cost, charged at both GiB-processed and object count 💵
$0.004 per 1000 objects processed
$0.05 per GiB processed 🚨
Here’s how I estimate the cost would look like:
For comparison, 1 TiB in S3 Standard would cost you $21.5-$23.5 a month. So this ends up around 37% more expensive.
Compaction can be the “hidden” cost here. In Iceberg you can compact for four reasons:
bin-packing: combining smaller files into larger files.
this allows query engines to read larger data ranges with fewer requests (less overhead) → higher read throughput
this seems to be what AWS is doing in this first release. They just dropped a new blog post explaining the performance benefits.
merge-on-read compaction: merging the delete files generated from merge-on-reads with data files
sort data in new ways: you can rewrite data with new sort orders better suited for certain writes/updates
cluster the data: compact and sort via z-order sorting to better optimize for distinct query patterns
My understanding is that S3 Tables currently only supports the bin-packing compaction, and that’s what you’ll be charged on.
This is a one-time compaction1. Iceberg has a target file size (defaults to 512MiB). The compaction process looks for files in a partition that are either too small or large and attemps to rewrite them in the target size. Once done, that file shouldn’t be compacted again. So we can easily calculate the assumed costs.
If you ingest 1 TB of new data every month, you’ll be paying a one-time fee of $51.2 to compact it (1024 * 0.05).
The per-object compaction cost is tricky to estimate. It depends on your write patterns. Let’s assume you write 100 MiB files - that’d be ~10.5k objects. $0.042 to process those. Even if you write relatively-small 10 MiB files - it’d be just $0.42. Insignificant.
Storing that 1 TB data will cost you $25-27 each month.
Post-compaction, if each object is then 512 MiB (the default size), you’d have 2048 objects. The monitoring cost would be around $0.0512 a month. Pre-compaction, it’d be $0.2625 a month.
📁 S3 Metadata
The second feature out of the box is a simpler one. Automatic metadata management.
S3 Metadata is this simple feature you can enable on any S3 bucket.
Once enabled, S3 will automatically store and manage metadata for that bucket in an S3 Table (i.e, the new Iceberg thing)
That Iceberg table is called a metadata table and it’s read-only. S3 Metadata takes care of keeping it up to date, in “near real time”.
What Metadata
The metadata that gets stored is roughly split into two categories:
user-defined: basically any arbitrary key-value pairs you assign
product SKU, item ID, hash, etc.
system-defined: all the boring but useful stuff
object size, last modified date, encryption algorithm
💸 Cost
The cost for the feature is somewhat simple:
$0.00045 per 1000 updates
this is almost the same as regular GET costs. Very cheap.
they quote it as $0.45 per 1 million updates, but that’s confusing.
the S3 Tables Cost we covered above
since the metadata will get stored in a regular S3 Table, you’ll be paying for that too. Presumably the data won’t be large, so this won’t be significant.
Why
A big problem in the data lake space is the lake turning into a swamp.
Data Swamp: a data lake that’s not being used (and perhaps nobody knows what’s in there)
To an unexperienced person, it sounds trivial. How come you don’t know what’s in the lake?
But imagine I give you 1000 Petabytes of data. How do you begin to classify, categorize and organize everything? (hint: not easily)
Organizations usually resort to building their own metadata systems. They can be a pain to build and support.
With S3 Metadata, the vision is most probably to have metadata management as easy as “set this key-value pair on your clients writing the data”.
It then automatically into an Iceberg table and is kept up to date automatically as you delete/update/add new tags/etc.
Since it’s Iceberg, that means you can leverage all the powerful modern query engines to analyze, visualize and generally process the metadata of your data lake’s content. ⭐️
Sounds promising. Especially at the low cost point!
🤩 An Offer You Can’t Resist
All this is offered behind a fully managed AWS-grade first-class service?
I don’t see how all lakehouse providers in the space aren’t panicking.
Sure, their business won’t go to zero - but this must be a very real threat for their future revenue expectations.
People don’t realize the advantage cloud providers have in selling managed services, even if their product is inferior.
leverages the cloud provider’s massive sales teams
first-class integration
ease of use (just click a button and deploy)
no overhead in signing new contracts, vetting the vendor’s compliance standards, etc. (enterprise b2b deals normally take years)
no need to do complex networking setups (VPC peering, PrivateLink) just to avoid the egregious network costs
I saw this first hand at Confluent, trying to win over AWS’ MSK.
The difference here?
S3 is a much, MUCH more heavily-invested and better polished product…
And the total addressable market (TAM) is much larger.
Shots Fired

What we’re seeing is a small incremental step in an obvious age-old business strategy: move up the stack.
What began as the commoditization of storage with S3’s rise in the last decade+, is now slowly beginning to eat into the lakehouse stack.
Like this so far?
Subscribe to not miss out on future issues!
Did Iceberg Win? 👑
Some notes on Iceberg announcements I have include:
Aug 2023: Snowflake announces Iceberg support in their unified tables
March 2024: Confluent announces Iceberg support (Tableflow) in Kafka
But beside that - the open table format wars have been going on for a while.
It marked the rise of the so-called headless data architecture, where the storage layer (data) is decoupled from the query layers (engines) that use it. 💡
Despite being decoupled, the two layers will always be indirectly tightly coupled because efficiency in the query layer relies deeply on how the storage layer is done. (e.g optimizations that allow for data to be fetched efficiently for faster querying)
Because the table format essentially defines the storage layer, you had big dogs like Snowflake and Databricks aggressively competing with each other on the table formats.
Let’s not forget the absolutely humongous acquisition Databricks did by spending $1-2 BILLION on a company that was raking in $1-5M/yr. It’s precisely this competition that resulted in them outbidding each other for Tabular (a company founded by the Iceberg creators).
Talk about a revenue multiple…
I covered the story in a viral post here:
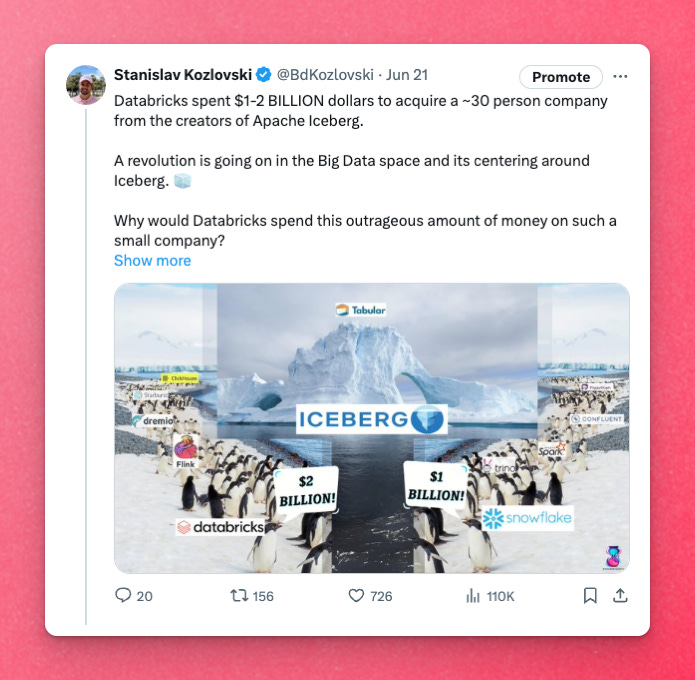
💙 LinkedIn Link
💚 Twitter/X Link
In my opinion, that is the seminal moment when Iceberg won the open table format war. When Iceberg’s main competitor - Databricks Delta Lake - shelled out this outrageous sum to acquire the creators of Iceberg.
AWS stood, watched and ate its popcorn. 🍿
In classic AWS fashion, they don’t compete in the protocol war.
They wait for it to settle (or show signs of it), then just come in and eat the cake with their scale.
So yes, I think Iceberg did win. 🎉.
I realize this comes as a bitter truth to all the people that bet on the competitor(s), and I’m happy to be proven wrong - but it seems obvious to my neutral eyes.

A Pyrrhic Victory?
(for those that aren’t aware of the term)
Let’s not forget why Iceberg is the buzz to begin with. It’s an Open Table Format.
The open table format war was precisely around that - openness. The idea was that:
Storage and compute products should be largely interchangeable and easily swapped, by using open standards like Iceberg.
The Open Table Format revolution sells you the following narrative:
zero copy - share your database’s storage by storing it in one place but using it from different query engines (avoids copying data and the insane network costs associated with that)
this is a much bigger proposition that we won’t dive into, but it essentially promises you both a data warehouse and data lake (coined the data lakehouse in classic industry jargon) with the same storage layer
openness - avoid lock-in by being able to easily swap query engines
also increase interoperability between tools, therefore reducing complexity and cost by allowing you to use the right tool for the job
It sold you the narrative that YOU control your data and are free to port it anywhere. In other words, you.
Is The Narrative Alive?
I think yes, but there will always be a tug of war.
The goal of every infrastructure company is to lock you in.
Never forget that, despite what they say. It’s the clear incentive for everybody.
The most successful infrastructure software company is called Oracle and it is notorious for its bad practices. While companies don’t want the bad reputation associated with it, they definitely salivate over their business.
So how are companies trying to lock you in with an open table format?
The metadata.
📖 The Catalog
An Iceberg Catalog is a piece of software that manages a collection of Iceberg tables and most importantly - its metadata.
Recall that a table is simply a collection of files - so the metadata is the source of truth of what constitutes a table. It is the equivalent to the relation database’s information_schema - without it, query engines would never be able to make sense of the data.
A catalog is essentially a metastore that also gatekeeps access to your Iceberg tables.
To mutate a table, you have to go through the catalog. You can read without it though
This has many benefits, like:
access control - define and enforce your security in one place
thread-safe access (to the root Iceberg metadata file)- allow multi-engine architectures via atomic transactions

That’s what locks you in.
If you define a gazillion security policies in the catalog’s proprietary format and it ends up storing other additional metadata - good luck moving to another provider.
And most certainly we have seen a battle there. It’s not an accident that weeks before the Tabular acquisition we saw major move in the Catalog wars:
June 3: Snowflake’s Open Source Polaris Iceberg Catalog announced
June 4: Databricks acquires Tabular
June 13: Databricks’ Unity Delta Catalog open sourced
This is amidst a gazillion other existing catalogs, like Starburst Catalog, Hive Metastore, JDBC, Project Nessie, LakeKeeper, AWS Glue and more I’m missing.

There is not one canonical catalog and that’s a problem - it’s huge overhead to compare between each and choose. Plus it’s a huge maintenance to maintain client libraries in all the different languages that the catalog may be implemented in.
To be fair, Iceberg saw the proliferation of engine programming languages required to operate with and has attempted to standardize on a given REST API for Catalogs. (since version 0.14.0 - July 2022). Adoption of this REST API has been good. (Lakekeeper, Nessie, Gravitino, Starburst, Dremio, Databricks, Snowflake)
As far as I can tell, any implementation of this Catalog interface is a catalog.
S3 - Yet Another Catalog
S3’s Tables Catalog is yet another catalog implementation. It implements the Iceberg Catalog interface in Java - by implementing the abstract BaseMetastoreCatalog. (I’m really not sure why they didn’t implement the REST API)
Basically a wrapper on top of the S3 Tables API.
There is one big differentiator here - access control.
AWS provides you the SAME authentication scheme (IAM Policy) that you’re:
used to
already a heavy user of (automation, etc.)
governs both your data files and your Catalog APIs
So setting up a separate catalog suddenly becomes extra effort in duplicating/maintaining access policies that must be justified.
How will S3 try to lock you in?
They have a lot of verticals they can try to do so in, namely:
the RBAC-like IAM policies they offer for table-level access control
their own API
the table maintenance features they offer on top
better performance via underlying S3 optimizations
Will Neutrality Die?
The Iceberg community already took a bittersweet L with the Tabular acqusition.
It’s ironic - Tabular had a very good blog post called “The Case for Independent Storage”.
There, Ryan Blue made the very strong argument that the industry needs and benefits from a neutral catalog provider, because its incentives would be aligned with the customers.
“I strongly believe in independent storage because I’ve seen the benefits first-hand. Our customers routinely see 30-60% savings from automatic tuning, and because we are neutral, these benefits apply across all compute environments. They’ve told us horror stories about tables that weren’t clustered, so every query was a full table scan and needlessly cost an extra $5 million per year. When you buy compute and storage from the same vendor, that company has little incentive to find and fix these types of problems. But that’s exactly what an independent storage vendor can and should do.”
- Ryan Blue
Not only that, but vendors can make their storage solutions more performant with their own query engines, or simply less performant with foreign query engines.
While some people were skeptical at the time of acquisition that now 2/3 of the open table format are “owned” by one company (Databricks) - the Iceberg community seems somewhat diverse.
Only 3/16 Iceberg PMC members were part of Tabular, and the top contributors were somewhat well split between Tabular, Dremio, Apple and a few others.
$ git clone https://github.com/apache/iceberg && cd iceberg
$ git shortlog --since=2022 --summary --numbered --all --no-merges | head -20
350 Fokko D. (Tabular)
184 Anton O. (Apple)
179 Eduard T. (Tabular)
142 Eduard T. (Tabular)
123 Ajantha B. (Dremio)
68 Ryan B. (Tabular)
58 Steven Z. W. (Apple)
56 Amogh J. (Tabular)
51 Bryan K. (Tabular)
49 Manu Z. (Unknown)
48 Amogh J. (Tabular)
43 Prashant S. (Amazon)
40 Xianyang L. (Tencent)
37 Szehon H. (Apple)
34 Robert S. (Dremio)
33 pvary (Apple)
30 Daniel W. (Tabular)
30 Kyle B. (Tabular)
29 Yufei G. (Apple)
28 Hongyue/Steve Z. (Apple)
$ # ^^ last names truncated and org name added(source for the Table is from Gilles Philippart, June 2024)
While there was concern that Databricks might have tried to steer the project more into its own lane, this action from Amazon is likely to result in push-back to any such endeavours.
If anything, the native S3 support is likely to invite more contributors from Amazon and by extension - the other two clouds.
I will be posting more in this letter, as it allows me to write in a more free-form style and include a ton of references. I find that freeing.
To NOT miss out on future issues: subcribe 👇
Nevertheless, feel free to check the other places I post:
https://blog.2minutestreaming.com/ - my flagship newsletter where every post is a carefully-curated, highly-polished strict 2 minute read (up to 476 words)
Noteworthy is that this is me assuming their compaction algorithm. They don’t share how it works, so who knows how many times it processes and bills you for the same GiB.
Ryan blue saying a vendor who controls both storage and query engine will not be incentivized to optimize storage for the query engine does not hold good for Big query. But the optimization of storage works only for Big Query engine that way he is right.