This is a community that Chia-Ping founded around August 2023. It started around with 100 people (friends) and has since grown 50x+.
The current metrics:
5000 participants
15,000 Slack messages/month
10 meetings/week
20+ committers
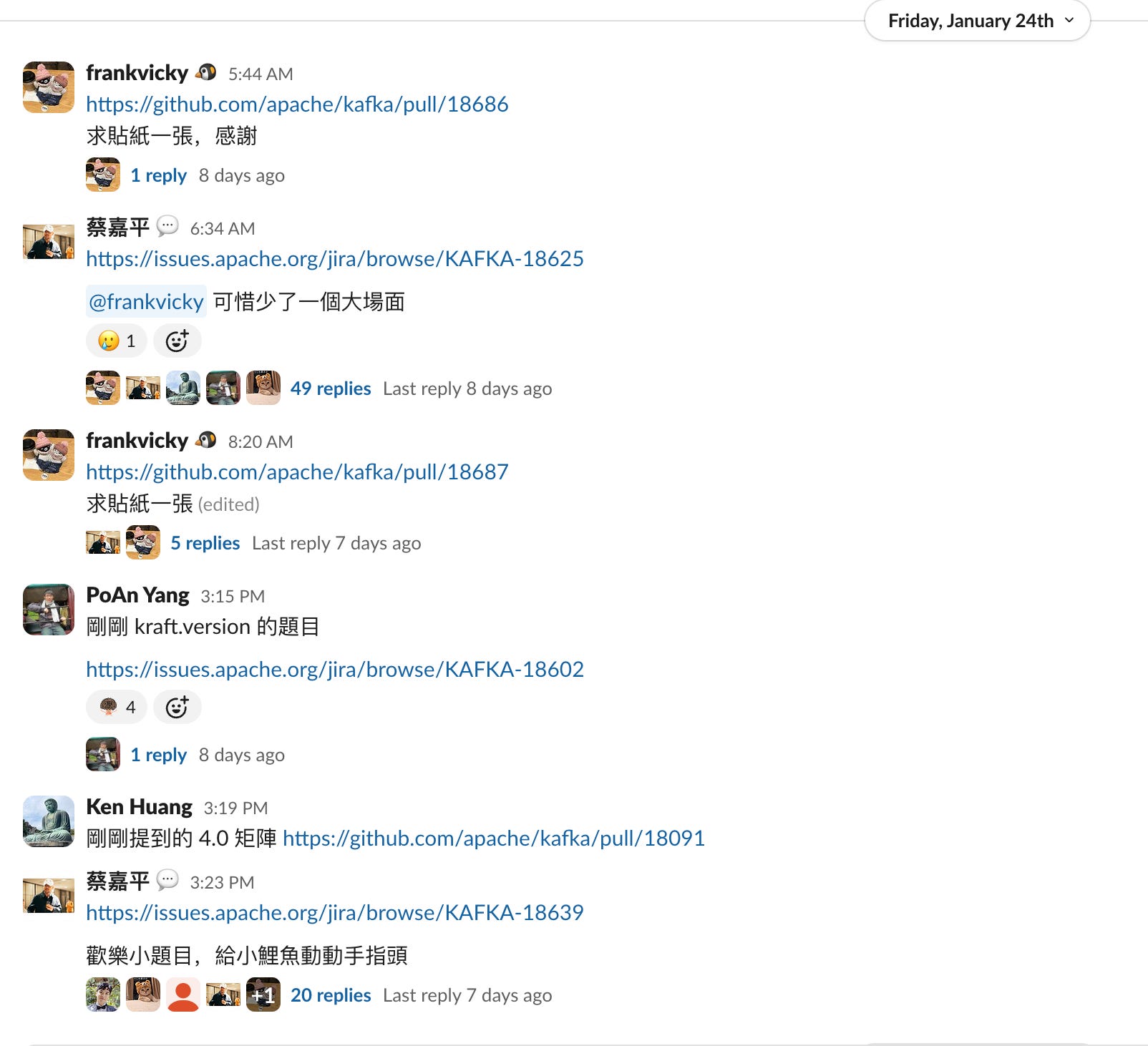
I joined their Slack and was blown away by the activity. It has multiple channels for different open-source projects.
The Kafka channel was super active - every day you would see discussions on 5+ different JIRAs.
just a regular day
The supported projects are Apache Kafka, Apache YuniKorn, Apache Gravitino, Apache Airflow, Apache Ozone, Apache Datafusion, Flyte, KubeRay & Ray, and Liger-Kernel, with each project having 1 to 3 mentors.
The community hosts a weekly tech talk on Saturdays and a book club every Wednesday.
源 stands for “Open Source” (it means Source)
An Interview
Needless to say, I was super interested. So I sat down and did a group interview with a few of their most active Kafka members.
We had a very long discussion and talked about a range of topics. To keep it engaging, I have taken excerpts from the discussion and edited the responses for clarity.
The interview was made between me and 5 other engineers!
First - a quick intro.
I’ll include a few words people shared about themselves, their time in the Kafka world and also the number of merged PRs they have in the project.
Don’t take this the wrong way - merged PRs are not the end-all-be-all metric.
There are a lot of other important ways contributors add value, namely: KIPs, KIP reviews and PR reviews; but also more.
It’s not a race. And if it were - it would be super hard to compare impact.
Take this as an easy-to-track vanity metric that gives you a sense of their activity. Nothing more. Effort cannot be faked.
To start off, I have 6-7 years of experience with Kafka and 85 merged PRs in the Apache project.
You will see soon enough that number is the lowest out of the group!
chances are if you post a PR in Kafka… Chia-Ping is going to review it
Chia-Ping:
I'm a bit of an odd person who often feels bored with life. So, while pursuing my PhD, I started contributing code.
Apache Kafka is widely used in Taiwan, and I thought learning Kafka and contributing would allow me to help friends with their Kafka issues.
After becoming a PMC member and then an Apache Member, I found myself bored again and left the open-source community to start my own company.
A year later, I realized that Taiwan lacked a community that encouraged engineers to join open source. So, I invested some of my company's money to start "opensource4you."
Besides hosting this community, I was also a mentor for Apache YuniKorn in its early stages. After mentoring three YuniKorn committers, I started another group focused on Apache Kafka.
This is what brought me back to the Kafka community - I needed to find valuable issues for my mentees. I also needed to re-learn Kafka to share my Kafka knowledge with the group.
Stan:
Love it! Are you getting bored now?
Chia-Ping:
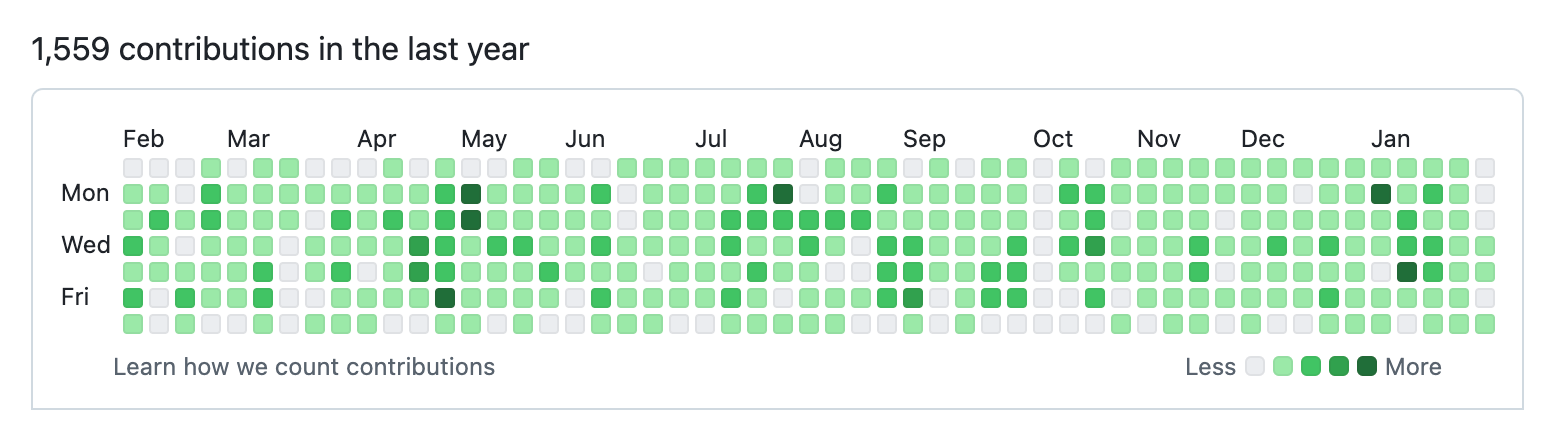
Honestly, I'm a bit bored now. I've created about 600 issues and reviewed roughly 1600 commits. Additionally, our team has contributed approximately 900 commits.
My last task here is to help them become Kafka committers.
I hope my team members don't feel they're wasting their time contributing code to Kafka in their spare time.
Stan:
That’s crazy. And I see you are still very active both in Kafka and mentoring your community.
Chia-Ping:
I normally review more than 10 PRs every day.
Reviewing code is fun for me, as I can learn a lot from other developers' PRs.
Stan:
No kidding! LOL. I saw your GitHub activity and it’s 92% reviews!
Do you encourage your mentees to review PRs too?
My best advice for any engineer ramping up is to spend a lot of time and effort reviewing code.
That’s one of the best ways to learn the codebase, familiarize yourself with conventions and to start thinking like a senior engineer.
It also helps us scale the project.
Chia-Ping:
Yes, I always encourage them to review PRs. Jun [Rao] gives the same suggestions too. Additionally, that is the necessary condition to be promoted to a PMC member I think.
Stan:
And a committer! I reviewed a lot back in the day and it was crucial for my nomination.
Chia-Ping:
I will request them to review 5 PR every day if they don’t get promoted this time. 😄
I’ve been involved with Kafka for a little over a year now. I got into open source to sharpen my technical skills, and the best way to do that is by investing time in well-known projects.
Kafka is famous for its performance, stability and scalability, and I wanted to understand how it achieves that!
It just so happened that Chia-Ping founded OpenSource4U and was willing to mentor people in Kafka, so I joined in. Still learning and improving!
I'm always enthusiastic about distributed systems. However, even if I were to join a large company, it wouldn’t be guaranteed that I can join the core team that solves the high QPS problems.
That's why I participate in Apache Kafka. It lets me touch these kind of challenges directly and learn how Kafka developers solve problems.
I started to contribute Kafka since March 2024. I hope to have a chance to join a team which works on distributed systems in the future.
Stan:
That’s such a good point! You can just “insert” yourself into the distributed, remote open-source core team of a high QPS system like Kafka and become an expert. (if you work hard enough at it)
Just a common story started as a coding bootcamp graduate with a history degree. I struggled with leetcode and looked for ways to improve my technical skills.
In Taiwan's job market, it's challenging to secure a good position if you are not a leetcode guy. While browsing through hundreds of job descriptions daily, I noticed a common keyword: Kafka. That's how it began.
I invested in some udemy courses to learn about it, but proving my understanding and expertise was still challenging. I never used Kafka in my day job.
In early 2024, I found this community by chance. During online discussions, I realized something unique - unlike most Taiwan OSS communities, people here weren't just promoting the tech, they were actively contributing to it.
I made a career transition from a Japanese chef to a software engineer three years ago.
When I graduated from the bootcamp and started job hunting, my friend mentioned Kafka to me. At that time, I couldn’t even set up a Kafka server properly, I didn’t understand its practical applications.
In my experience, there are two main paths to securing a good software engineering position:
either excelling at LeetCode
or being exceptionally skilled (through reputation or technical expertise).
I’m open to practice LeetCode - in fact, I’ve been solving LeetCode problems daily for almost a year, before I started contributing to Kafka. However, practicing alone can become monotonous, and the skills developed through LeetCode often don’t directly translate to real-world work scenarios.
I began contributing to Kafka in April 2024. Before starting, I took courses on Udemy to understand Kafka’s functionality.
What keeps me actively contributing in Kafka is that I think it is interesting. I can learn a lot from community. OpenSource4U has created an environment that’s particularly friendly to new contributors, making the learning process both enjoyable and enriching.
Stan:
That is so cool! What was the specialty meal you prepared as a Chef?
Jiunn-Yang:
I worked at a Kaiseki restaurant, which specializes in traditional Japanese haute cuisine.
Kaiseki dining is characterized by a carefully crafted multi-course meal. In our kitchen, different chefs were responsible for specific dishes.
My primary responsibilities focused on yakimono (grilled dishes) and agemono (deep-fried dishes).
Stan:
And what is the biggest similarity between being a chef and an engineer?
Jiunn-Yang:
I can explain this from two perspectives: activities outside of work and behaviors within the workplace.
activites outside of work: Just as chefs need to stay updated on new culinary techniques and trends, software engineers must continuously learn and adapt to new technologies.
In both fields, dedicating time outside of regular work hours to improving one’s skills is essential for growth and excellence.
behaviors within the workplace: Team collaboration and time management go hand in hand.
In a kitchen, different stations must coordinate seamlessly to deliver a complete meal—just as in software development, where specialists like frontend, backend, and DevOps engineers work together to build a fully functional application.
Effective time management is also crucial; prioritizing tasks and allocating time wisely ensures a smooth workflow and overall efficiency.
Stan:
Those were the intros.
I just want to emphasize. This is some insane level of activity. For context, I’ve been in Kafka since 2018 and only have 85 merged PRs in the open source repo (and 40 closed ones, ouch).
Some of these guys have been in for 10 months and merged 164!
Keep in mind this isn’t their full time job either!
The level of effort is on another level.
I sensed it joining the Slack community. Every day the Kafka channel there has 6-7 JIRAs actively being discussed. (including weekends)
If you’re an employer searching for Kafka engineers, you’d be out of your mind to pass on these people. Motivation is the main determinant of a success in an individual, and the motivation here is out of this world.
Now we will jump into some of the discussions we had:
Good Impressions
Stan:
What has made an impression on you in Kafka?
Kuan-Po:
One thing that really stood out to me about Kafka is how much attention it gives to details and its almost obsessive pursuit of perfection.
Every design decision is carefully thought out to maximize performance and handle edge cases properly.
I was really confused how it [a distributed system] keeps messages in order while still maintaining high throughput. Later, I realized Kafka solves this using partitions and keys.
An example—there might be millions of users, each with a unique key. By making sure messages with the same key always go to the same partition, Kafka can guarantee ordering for each user.
And if there are too many users, we can just increase the number of partitions to scale up throughput! This idea reminded me of the divide and conquer strategy. When I first saw how it worked, I thought it was such an elegant design.
Stan:
💯. A lot of people underappreciate or otherwise take for granted Kafka’s design, especially after years of exposure to it. There is a reason Kafka is the project it is today. It was very elegant and innovative, with a lot of thought put behind performance and scalability.
When LinkedIn announced it was processing trillions of messages a day in 2015… it was a big deal!
Kuan-Po:
Another thing that really impressed me is how much effort the community puts into solving even the rarest edge cases.
A good example is KIP-966: Eligible Leader Replicas. It addresses a situation where, in extremely rare cases, an unclean shutdown could turn local data loss into a global data loss—meaning that even committed data could be lost across all replicas.
The chances of this happening are incredibly low, but the Kafka community still put in a huge amount of effort to fix it properly.
I feel like this kind of mindset—the constant push for improvement, even in areas that most systems wouldn’t worry about—is a big part of what makes Kafka so successful.
Stan:
I believe that KIP was a response to a popular RedPanda blog bashing Kafka for not using fsync. I believe it was a bit of an overhyped rare edge case - you needed all 3 of your replicas to die in order to risk losing data like that.
As you allude to, the case was that if you had an ISR of 1 replica left standing (the other 2 are under-replicated), a hard restart (e.g power cut) could cause the broker to lose data (acked messages), because they may still have been in page-cache and not flushed to disk at the time of the power cut.
Nevertheless, this is the benefit of working on a massive open source system that’s basically used in every large company in the world.
Things you wouldn’t expect to happen - happen.
And they cost a lot! So it becomes worth it to invest time in fixing every possible little problem. Which is what makes it fun 🙂
Chia-Ping:
I love those edge cases because they always inspire me to rethink the current architecture. They can also reveal many valuable issues.
Hardest Thing to Learn?
Stan:
What was the hardest thing you had to learn in Kafka initially?
Kuan-Po:
When I first started, I felt overwhelmed trying to understand how everything in Kafka fits together. There were so many components—producers, consumers, Kafka logs, ZooKeeper, KRaft, Kafka Streams, Kafka Connect...
There are plenty of articles explaining these things, but understanding what each component does and actually diving into the code to see how they work are two very different things.
Later, I realized that instead of trying to grasp everything at once, it was better to start by becoming a good user first.
A simple way to do that was by contributing tests, and then gradually expanding my understanding from there. I started with Kafka’s core modules—Kafka client and Kafka core—making sure I understood them well before moving on to Connect and Streams. Taking it step by step like this made it much easier to put everything together and see the bigger picture.
Stan:
Later, I realized that instead of trying to grasp everything at once, it was better to start by becoming a good user first. A simple way to do that was by contributing tests, and then gradually expanding my understanding from there.
I love this quote. That’s 100% spot on! Always start small, and just keep going. Things get clearer the more effort you put in.
I was also really lost in the code back in the day. What personally helped me was to figure out the KafkaApis.scala class - basically find the entry point of Kafka’s requests.
From there I could easily track down everything else if I just dove into the code enough!
Stan:
Another part that was really hard for me was to figure out the whole partition leadership and failover thing.
I wanted to know the exact dance of requests - who sends the LeaderAndIsr request, to who does it send it, when does it send it, etc.
The code was tricky to read and there was a lot of internal knowledge that was just stuck in the minds of the very senior engineers.
To an extent, it’s clarifying these things that motivated me to write more - so others don’t have to go through the same.
…
Kuan-Po, What was the hardest class you had to read so far in Kafka?
Kuan-Po:
I want to change this question a little bit to “What is the most important class I've had to read so far”, as most classes seem difficult to understand at first
When reflecting on the hardest class I've had to read so far in Kafka, it would be UnifiedLog.scala and KafkaConsumer.java
UnifiedLog.scala: I consider this class fundamental to Kafka, as it includes key concepts like indexing and the internal mechanics of Kafka’s log handling, which are critical for understanding how Kafka stores and processes messages.
KafkaConsumer.java : KafkaConsumer stands out as more complicated compared to the KafkaProducer. While the Producer has its complexities, the Consumer introduces more intricate behavior, such as offset management, consumer group coordination, and message delivery guarantees. This complexity is due to the need for managing various consumer states and ensuring fault tolerance across distributed consumers. BTW now we have another consumer called AsyncKafkaConusmer.java introduced by KIP-848, and it will be enabled by default in Kafka 4.1.
These two classes have helped me gain a better understanding of how Kafka works. If I were to recommend classes for beginners to focus on, I would suggest these two.
Stan:
Agreed both classes are important. For me, in terms of impact, it was KafkaController. I spent a lot of deeply focused work sessions one summer in London trying to understand the partition reassignment flow there.
I was a bit sad to see it get deleted as part of going to KRaft 🥲
Largest Contributions 🏆
Stan:
What’s the hardest or most impactful thing you’ve contributed so far?
TengYao:
I think the hardest thing is the log4j2 migration. As we all know, it's a thankless job - do users or developers really care about which logging framework runs underneath? (If it works, don't touch it, right?) 😅
The original author submitted the PR and KIP in 2020.
After 4 years, Kafka was still stuck with log4j1 and forced to use reload4j (a fork of log4j1 created to solve security issues).
Since log4j3 is also going into beta, it will become even harder as time passes if we don't start migration immediately.
I took over this issue because I believed someone needed to continue working on it - it's essential for the community.
Moreover, as just a individual contributor in the community, I don't have any pressure and can do research freely. Honestly, I wasn't familiar with how log4j works behind the scenes, and being a long-evolved project, it has a lot of context. I'm doing the migration while learning this framework and trying to figure out the differences between versions 1 and 2.
It's not easy work, but thanks to opensource4you and the Kafka community, they've given me many suggestions and help while I work on this patch. Though it hasn't been smooth sailing, we still got the job done. (But I hope we don't need to do this again!
However, we still had to do some follow-up work on it. Since system tests rely heavily on logs, this PR actually broke tons of system tests...... 😬
I was worried it might get reverted due to breaking so many tests... but glad that with the helps from community, we have fixed all of these issues 😄
Stan:
haha, it’s never one PR! I know that too well 🥲
Special thanks to Chia-Ping, who spent lots of time troubleshooting with me.
Also, Piotr P. Karwasz, a PMC member of Apache Logging Services, provided valuable advice and context about log4j. I truly appreciate these amazing people, and I feel great about these unexpected connections made through OSS contributions. It's truly amazing that we could have such great cooperation and discussions through the internet without ever meeting each other in person. In the past, I never thought I would have the chance to connect with such talented and accomplished engineers.
Chia-Ping:
Piotr is a nice guy who has given us a lot of useful information about Log4j2. He also filed a PR as a follow-up to refactor the Kafka dynamic logger. He is so cool!
Stan:
I love this. That’s the power of open-source.
Thanks a lot for contributing this tough migration, TengYao!
In this KIP, we would like to have a signal in group coordinator to know when to trigger a rebalance (like rack change, partition number change, etc).
The original way cost lot of disk space, because it tried to store all subscribed topic details. In this KIP, we compared different strategies and got a balance between CPU / Memory / Disk usage.
CPU: we use a memory cache to keep the topic value we calculated, so we don't have redundant calculations here.
Memory: we share cache between different groups, so we don't store redundant data
Disk: we combine all subscribed topic hash as a single hash, so we minimize space usage.
Initially, I tried several approaches to solve this issue, but eventually realized none of them could really address the root cause. After discussions in the community, I decided to propose a KIP to modify the protocol introduced by KIP-848.
Since KIP-848 was still under development and would bring the next generation consumer, I was very excited about this opportunity. Moreover, this KIP is meaningful not only for Kafka but also for me personally - it's my first time proposing such an important change to Kafka.
The ConsumerGroupHeartbeat RPC is the core mechanism of the new generation consumer, so I believe KIP-1082 will bring significant benefits to Kafka users.
I hope they'll enjoy it after the async consumer is released! :)
Stan:
What is the async consumer?
TengYao:
The async consumer is a new consumer designed to work with the next generation group rebalance protocol proposed in KIP-848. In the past, the consumer rebalance protocol relied on thick clients, which became slow and unstable when consumer groups grew large due to group-wide synchronization barriers. KIP-848 introduced a new, truly incremental group rebalance protocol.
To work effectively with this new protocol, the async consumer was developed. I think its biggest benefit is the elimination of blocking between polling and rebalancing, as these operations now run on separate threads.
Time Zones
Stan:
Is the time zone ever a problem for you guys? I know when I worked with the US from the EU I had a lot of trouble with it.
Chia-Ping:
The time zone is definitely a problem for me.
My wife hates that I do open-source contributions. I guess the only reason she hasn't left me is that I do all the chores.
Other communities, like Apache HBase, have many active committers in Asia, which makes it easier for me to communicate with other developers.
In contrast, most active Kafka committers are in completely different time zones, and I feel that's another important reason why we need a "local" open-source community.
Stan:
keep doing the chores! 🤣
but I gotta say - I really love this man. You saw the timezone problem, and you took matters into your own hands to create the local community.
It is a great achievement and an inspiration for other open source projects! I hope to see it keep growing and develop more committers. It would be great for the project [Kafka].
Yes, time zone is a problem. Luckily, there are some Kafka developers live in EU (like David Jacot), so we have chance to cooperate from afternoon to evening in Taiwan.
Stan:
David is a world class engineer. I worked in the same team as him at one point, and also after due to the time zone.
We always spoke together about time-zone issues too.
Kuan-Po:
Time zones are definitely a challenge.
Most Kafka committers are in the U.S., which means PR reviews can sometimes drag on. Especially when a release is approaching and the issue I’m working on is a blocker, I sometimes just bite the bullet, sync with U.S. time, and sacrifice some sleep.
But I’m glad this doesn’t happen too often.
Plus, getting to work on blocker issues is actually pretty lucky—it’s a chance to make an impact and increase my visibility at the same time.
TengYao:
That's for sure - it's not easy to catch up with discussions and sync with other developers in NA and EU.
That's why we all truly respect Chia-Ping, it seems like he never needs sleep!I wonder if he secretly has many clones!
Stan:
I like the positive view, Kuan-Po! I did get a feeling Chia-Ping never sleeps too, LOL. (I chatted with him at ~4AM his time… 🥲)
Chia-Ping:
TengYao, you’re welcome to join my chore team 😄
Time Zone → Blockers ⏰
Jiunn-Yang:
Is the time zone ever a problem for you guys? I know when I worked with the US from the EU I had a lot of trouble with it
This reminds me of a funny experience. Once, I picked up a blocker issue and quickly made a fix based on the discussion on GitHub. After pushing my changes, I went to bed.
Initially, the discussion among a few senior developers was happening on a different PR, but for some reason, it eventually shifted to mine.
At the time, I didn’t fully understand the problem, so I ended up writing a rather strange solution.
One of the senior developers very politely commented, “Sorry, I don’t understand the change here,” and then force-pushed my PR with the correct fix.
When I woke up the next morning, I was shocked to see how much my PR had changed.
TengYao:
I remember that epic PR.
Chia-Ping:
Let me tell you an epic story.
In preparation for the 3.9 release, I raised an issue that 3.9 Kafka could not work with older servers in a specific use case. This was a blocker-level bug that absolutely had to be fixed for 3.9 – a perfect opportunity to showcase Jiunn-Yang’s skills.
I outlined a potential approach and then assigned Jiunn-Yang to submit the patch.
However, the guy was too tired to file the correct patch.
This resulted in Colin, Jun, and me spending time analyzing a strange patch while the author went to sleep...
Eventually, Colin started to modify his PR.
In the end, we couldn't go to sleep if there were blocker tickets assigned to us.
That is why our people from other [Slack] channels always say this Kafka channel is composed of crazy OSS boys. 🤣
Stan:
hahahaha, desperate times call for desperate measures!!!
Blocker issues are super stressful man, it’s not for the faint of heart
And this is where the timezone sucks so much. If we were all in the same time zone, it could be handled easier.
Biggest Pet Peeve / Annoyance 😡
Stan:
What’s your biggest pet peeve/annoyance with Kafka? Can be with the product, community, code, tests, etc
PoAn:
The pet peeve/annoyance is that KIPs don’t always reveal clearly how the underlying feature works.
For example, I didn't understand new group coordinator when I read KIP-848. I understand it after I watched your video and blog.
IIUC, KIP-848 introduces a new framework CoordinatorRuntime. However, if searching for keywords like runtime or framework, it only matches one word in the KIP.
I think we definitely need more articles to show technology details in Kafka.
Stan:
This type of thing is what motivated me to start 2 Minute Streaming - it’s a pet peeve of mine too! I think there are a few reasons for this:
KIPs change a lot after first being voted/discussed, and its easy to forget to update the KIP, especially when it becomes large/goes through a lot of iterations. I hate this too. I’d prefer if KIPs were hosted in GitHub with PR reviews acting as gates to mark them “complete”
KIP-848 actually does explain it from what I remember, I think I learned it entirely from there. But it’s very technically written and requires deep study to understand. Which is why I created the blog too, haha. It’s honestly rare to be a good engineer and concise technical communicator. Plus it takes quite a while to create the graphics and etc, and engineers would just rather code. And in the KIP, you actually shouldn’t be too concise - all details need to be covered
Nevertheless, I don’t think it’s an excuse. I believe it’s super important to have these things made as accessible as possible, because it eases ramp-up which:
helps attracts new engineers
onboards them faster & more efficiently
I guess that’s what happened with you when you read the blog/video!
Chia-Ping:
While it might conflict with existing business products, I believe an official GUI dashboard for Kafka would be invaluable, allowing users to easily monitor and manage their Kafka clusters.
Additionally, our lack of auto-rebalancing support creates difficulties when scaling our running cluster. We constantly struggle with manually reassigning partitions to newly added brokers.
Stan:
yes. an official GUI would be so good if the community. I have this meme that explains things perfectly:
It’s probably grown to 17 UI tools since I created it.
Additionally, our lack of auto-rebalancing support creates difficulties when scaling our running cluster.
Cruise Control fixes that mostly doesn’t it?
Chia-Ping:
Yes, it can cover the scenario I described. However, it is always better to have a “self-balanced” distributed system
Stan:
Yeah! It would be so nice if we just put Cruise Control inside Kafka!
TengYao:
We all know that some companies have commercial services built around Kafka, and they have employees contributing to upstream. Sometimes these commits might introduce issues due to insufficient review.
While I understand there might be time pressure, and reviewers might have more trust in colleagues' code, I believe we could avoid such situations by waiting for CI checks to complete and getting more thorough reviews.
Stan:
That’s really bad if people don’t wait for CI checks to complete just because they get reviews from colleagues. At Confluent this was always extremely discouraged, but some people simply do what they want (esp. when in a hurry).
I’ve probably done it too lol (but in internal repos only)
TengYao:
I remember that someone has committed to trunk directly
Chia-Ping:
I always assume that is a exception
What Would Be Most Impactful to Increase Productivity 🤔
Stan:
Another question - what do you think would be the most impactful thing that would help you be more productive in Kafka?
Chia-Ping:
short answer: more reviews
long answer: It seems to me that most active committers are heavily occupied with their "day jobs," making it difficult for other contributors to receive the attention and guidance they need from these experienced developers.
I've witnessed several instances of frustrated contributors who feel neglected by the community.
As an "amateur" committer myself, I strive to review PRs as much as possible, but realistically, I cannot address every single contributor's PR due to the demands of my own work and personal life.
Jiunn-Yang:
I totally agree. I often see some PRs where the committer gets pinged, but even after several weeks, no one pays attention to them.
Most committers are just too busy.
Kuan-Po:
Can't agree anymore, TBH, Most of my PRs get reviewed by Chia-Ping...
Chia-Ping:
Stan:
… It seems to me that most active committers are heavily occupied with their “day jobs,” …
Yes this is exactly it. I can tell you what this looked like to me.
When I was employed in Confluent, there simply isn’t any incentive to spend time on outside open source work.
I’m already busy and we have fun projects to do, I don’t care too much about this other person doing this random feature.
The root of the problem is that it’s really hard to be a good open source committer and maintain a day job. Both of these things are day jobs in of themselves.
Confluent was good in giving us space to contribute and valuing those contributions. They wouldn’t tell us not to spend time on the open source or something like that.
I think the answer is to get MORE committers!
Jiunn-Yang:
I also think that Jira is not very user-friendly. On top of that, the page loading speed is always slow, and files uploaded without any notification window (It’s easy to upload the wrong file).
I believe switching to GitHub Issues would be a better choice.
Stan:
Agree. It’s so hard to search there.
Another bad system is the Wiki. It’s clunky, slow and isn’t updated regularly.
I wish we did something with Markdown and in Github, similar to what Ethereum does for their EIPs. (example)
That way we can have PR reviews that ensure the KIP text matches exactly what is voted on, and future updates are explicit and seen. Today when the wiki is updated it’s easy to miss.
Chia-Ping:
I started a discussion about migrating to GitHub Issues, but it hasn't received a positive response.
Stan:
🥲
Kudos 👏
1 Kafka committer (also PMC Member) and 4 future ones
Massive thanks to Chia-Ping for bootstrapping both this large community and this tight-knit Kafka circle!
It goes to show that one person can create splash waves in open source software.
We now have 5+ active contributors to Kafka, for a total of more than 500 PRs merged in just over a year. Talk about impact! 💥
Bonus
There is another prominent Kafka contributor from Taiwan that I’d be remiss to not include here!
Luke Chen is a Kafka committer and PMC member who is also in this community.
He helped Chia-Ping when building it out, but didn’t continue being as involved. Although I do see him in the Slack channel, I interviewed him separately in DMs.
Time in Kafka: 5+ years
Kafka Committer
Kafka PMC Member
Stan:
Hey Luke!
I found out Taiwan has a large open source community around Kafka that Chia-Ping runs.
I am doing a group interview with some of the members there.
I know you aren't in that community, but you live in Taiwan as per my understanding and are such a significant contributor in Kafka it would be a massive shame if I didn't include you.
[…]
Luke Chen:
Yes, I know the open source community in Taiwan, and I had been working with Chia-Ping to build it up.
It's just that I don't have the passion like Chia-Ping has, I didn't continue on that.
But I talk with Chia-Ping and other members in slack from time to time, I’m really happy to see that the community is getting better and better!
Stan:
How many years have you been interacting with Kafka? What was the story that got you to it (out of all the possible other apache projects)
Luke Chen:
5 years.
The story is quite simple: our team was evaluating it and I never heard of it. Then, when I went to a job interview, they asked me about Kafka, which also surprised me. That let me decide to start to learn it!
No, not just learn it, I want to master it! But how? Then I decided to start to contribute to it. That's the story that got me into Kafka's world!
Stan:
Love the story and self-motivation!
My story was similar - I saw it in a Uber meetup and wanted to understand what it is; Opened the website and read "data streaming platform". I understood even less.
So I set out to dive into every resource I could find and create an article that explains it for people like me. That got viral and led me to an interview with Confluent.
Stan:
Is the time zone ever a problem for you?
Luke Chen:
Sometimes, but not too much.
Maybe it's because I'm already used to it since my ex-team is the collaboration between US, EU, and Taiwan.
The lesson learned from the cross-team experience is that when I opened a PR or review a PR, I'll try my best to make everything clear, so that the person in other timezone can get my thoughts quickly and clearly, to avoid unneeded confusion.
Stan:
Got it, so it's about effective async communication. I had to learn that the hard way myself too having mostly worked with the US West Coast exclusively.
It's a really good skill that carries over to many aspects in life.
Stan:
What was the hardest/most impactful thing you ever worked on Kafka? (can be a contribution, KIP, something internal, etc)
Luke Chen:
Tiered Storage. This is a feature that our customer kept requesting for, but you know, the KIP was proposed in 2020, but the implementation didn't have good progress at first. In 2022, I started to chat with the author and joined the PR implementation/review/discussion with other contributors. We finally made an early access in the end of 2023. And then made it production ready in 2024.
Stan:
What’s your biggest pet peeve/annoyance with Kafka? Can be with the product, community, code, tests, etc
Luke Chen:
I think it's that there are many forked kafka or re-written kafka in the market, which containing some proprietary features not included in the open source.
When seeing it, I always think we should also have it in the Apache Kafka for all the users.
Stan:
💯. Man I have so many thoughts here, I should probably write a full-blown article on it.
It’s really the double-edged sword of the open core business model, where it’s against the interest of the biggest Kafka committer employer to contribute too much to the open source (since it gives it to competitors for free).
But then again, that employer is the sole reason Kafka is where it is now, and they still contribute a ton.
I think it’s definitely up to us (the community) to pick the torch up, organize better and contribute some features. Every company uses Kafka, but little contribute. I wonder if we actually try whether we’d be able to organize some coordinated effort.
I think large companies like Amazon and Google, who profit from hosting Kafka, should up their game in open source contributions. Amazon has been taking some steps there from what I can tell. 👍
In particular, I’m really interested in seeing if Apache Kafka can implement the direct-to-S3 leaderless model for some topics. Also some form of native Iceberg/schema support.
These two would probably be the missing pieces to make sure Kafka is cemented as the tool to use for the next 10 years in data infrastructure.
🎬 Fin
Did you like this type of interview?
Smash the like button and maybe even share the article with any colleague you think may be interested!
I think this personalized touch is missing from the Kafka community and I’m happy to help amplify some of the voices in the Kafka space.
Thanks for reading. ~Stan
Do you have an active Kafka community where you live? I will be happy to feature you next!