

The Brutal Truth about Kafka Cost Calculators
you are conditioned to believe that Kafka is expensive


Intro
The open source streaming space is built on transparency, so when I see something wrong - I feel obliged to call it out.
I see it all the time. People take a certain provider’s words for granted and repeat the same type of disparaging narrative:
Kafka is slow. This product is 10x times faster than Kafka.
Kafka is expensive. This product is 10x times cheaper than Kafka.
But Kafka is an open source project. It can’t bite back.
It’s time we change that.
In this article, I will do a very deep dive into why users should be skeptical of any vendor-claimed cost savings with a focus on a particular vendor - WarpStream.
They used a cost calculator on their page to compare pricing between self-hosting open source Kafka and their system. As of writing, the calculator is extremely inaccurate in calculating Kafka’s cost.
It will be a fun one - we will scrutinize every single pixel change on the HTML and even do a PR review of the code changes!
At the end, I’ll announce a solution that should hopefully help with these things.
Grab a coffee and let’s dive in. ☕️
🧐 TLDR
Post-acquisition, WarpStream increased their pricing 1.5x-2.5x and through one blatant bug and a lot of subtle, questionable changes on their calculator, made it look like it’s still 80% cheaper than Kafka by doubling its price too (off an already very exaggerated base).
Under my calculations, the actual Kafka cost is overstated by a factor of three (2.8x).
If you account for optimizing your Kafka deployment, the cost becomes overstated by a factor of five and a half (5.6x)
This is all without accounting for cloud discounts either - a key benefit of BYOC if you are to go that route.
If you compare to other clouds, you’ll actually see that hosting Apache Kafka yourself is cheaper than using WarpStream.
I announce AKalculator - an independent Apache Kafka cost calculator that isn’t incentivized to show you inflated costs.
Every single summarized bullet point is in the Appendix in a referrable format.
The Story
WarpStream was an innovative Kafka-compatible data infra startup that was marketed with its cost savings capabilities citing “10x cheaper than Kafka” and “80% cheaper than Apache Kafka”.
They prove these claims through a cost calculator accessible on their website.

These claims sound directionally correct.
everything is super expensive in the cloud
Kafka does rack up a ton of network costs
Kafka without Tiered Storage does use a ton of disk, and that isn’t cheap either.
And WarpStream removes the network and disks costs through a very innovative design that avoids inter-zone networking and local disks.

So it must add up!
But I was always a bit skeptical of the whole thing.
How much cheaper can you actually be?
Kafka has a lot of knobs you can tune to lower cost like Tiered Storage (KIP-405) and Fetch from Follower (KIP-392).
Plus, how can a start up reconcile the growth expectations that comes with VC investment while selling a product at 10x cheaper than the open source cost?
Regardless of my opinion - this proved to work good for them. A lot of their blog posts went viral and they gathered a lot of attention.
So much so that just 13 months after their incorporation, they got acquired by Confluent for $220M in September 2024.
I was shocked.
While I was still working in Confluent (I left June 2024), there was active development for a competitor product that used the same direct-to-S3 design. Confluent Freight was released during Kafka Summit Bangalore in May 2024 and promised to be up to 90% cheaper.
So I was confused - why would they acquihire the competitor?
A bit after that, I saw this LinkedIn post by Denis Coady:

I thought it was a hilarious meme.
I then dived into it to see the actual changes and sure enough they did actually double the pricing.
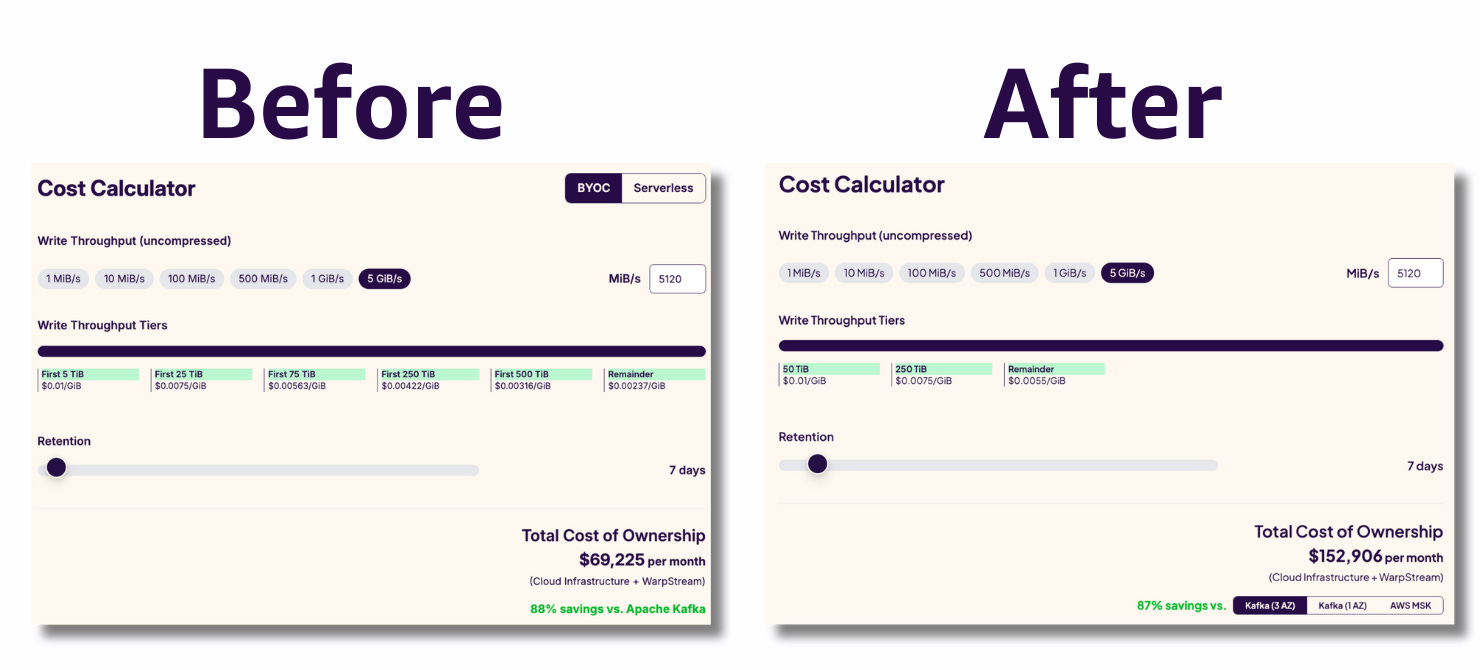
This surely leaves a bit of a bad taste. But I’m a big believer in free markets, so I think it’s totally cool for them to do whatever they want with their pricing.
What any careful reader may have noticed is something more subtle - the WarpStream cost increased by 2.2x but the cost savings percentage against Kafka changed by just -1%.

That’s weird... the only way that could happen is if Kafka’s costs increased by 2.2x too.
Something smells fishy.
Let’s explore. 👇
Breaking Down (Costs)
Luckily, the calculator gives us a pretty clear breakdown of the costs:

In this old version, the calculator assumed that Kafka would:
be deployed with 110 r4.4xlarge instances - $86,268/m
cost $241,920/m a month in inter-zone networking fees
use 3,628,800 GiB (3.46 PiB) of EBS at $290,304/m
These are already huge costs! You’re looking at $7.42M a year.
That’s 1.7x times more expensive according to my calculations. But we can save that for later. Let’s continue with the new version…
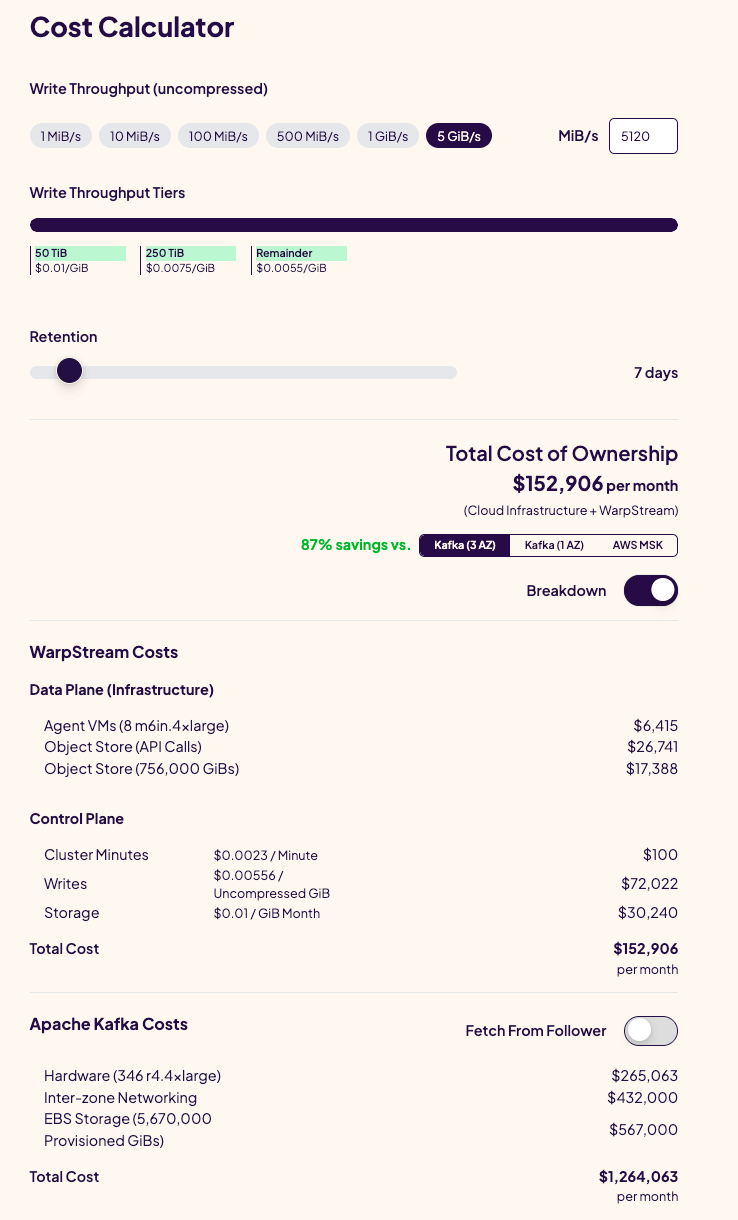
The Kafka cost literally doubled. It was 616.5k a month and now it’s 1.264M a month 😵💫
I’m pretty confident Kafka can be at least 3.5x cheaper than that, and with the right configs - 7x cheaper. Again - I’ll prove this later.
For now - let’s inspect the differences in detail:
A lot of things here don’t make sense to me.
Why does it deploy three times as many instances?
Why did the inter-zone networking cost almost double? (1.8x)
Why did the amount of provisioned storage increase ~1.6x, but the same storage price increased ~2x?
Why did the Apache Kafka cost double?
It’s All About Assumptions
Any infrastructure software cost calculator has to make some assumptions about the way that system is set up. It’s hard - if not impossible - to have a one size fits all.
WarpStream nicely lists out their assumptions publicly under the calculator.
Let’s see what they are. Maybe they changed?
Pre-Acquisition Assumptions

Let me summarize the interesting bits for you:
✅ max 10 MiB/s produce per vCPU - fair
✅ 3x consumer fanout traffic - fair
definition: this basically represents how many times do you consume the data you produce. if you produce 1 GiB/s and assume a 3x consumer fanout - your consumers are reading 3 GiB/s.
✅ 5:1 compression ratio - fair
definition: every 5 MiB/s of input results in 1 MiB/s actual traffic/storage for the underlying system.
✅ 3-zone Kafka deployment - fair
✅ 1/3 producers and consumers are zone aligned - fair
🤔 max 32 TiB EBS deployments, using “lowest-cost offering” gp2
🤔 target EBS utilization is 50% to give reaction time in case write throughput increases
Before we inspect what changed, a few issues stand out here already:
It’s the Disks
❌ gp2 is not the lowest-cost offering by any means.
It is the older generation SSD offered by AWS EBS and is superceeded by gp3. gp3 is $0.08/GiB vs gp2’s $0.1/GiB (20% cheaper).
SSDs are not the lowest cost offering - HDDs are.
EBS offers very price-competitive HDDs at $0.045/GiB or even $0.015/GiB. Despite having worse performance, in this specific deployment and comparison I think they’re a perfect fit. SSDs are massively overkill. (we will get back to this later)
❌ 50% of free space is a worthwhile goal, but it unnecessarily penalizes large deployments.
You wouldn’t want to have 16 TiB free out of a 32 TiB drive - that’s pretty wasteful.
If you have 110 nodes with 1 GiB/s throughput, that’s 27.9 MiB/s of post-replication writes per broker. At double the throughput, it’d take you 7 days to fill the disk.
It’s interesting that same paragraph says “We have gone out of our way to model realistic parameters… Our objective is NOT to skew the results in favor of WarpStream…”.

They’re saying that a 32 TiB gp2 SSD can’t sustain just 27.9 MiB/s of writes if you were to have a high number of partitions?
These disks support 250 MiB/s at 16,000 IOPS.
Even if your IO size was a microscopic 10 KiB, the disk would support 152 MiB/s. That’s 5.4x more than what we need here.
You’d be able to support 15,564 partitions writing at 10 KiB IOs.
Except that Kafka doesn’t use such microscopic IO sizes, its pagecache-first write design (fsync is off) means the OS batches the writes into larger IOs.
Not to mention those disks aren’t the cheapest to begin with.
The CHEAPER gp3 SSDs can go up to 1,000 MiB/s.
I don’t see where these “ton of assumptions in Kafka’s favor” are.
I don’t see how there is no objective to skew the results in WarpStream’s favor.
But keep reading and you’ll see it gets worse.
Post-Acquisition Assumptions

A few changes can be seen:
✅ EBS volumes were capped to 16TiB of size (not 32 TiB) because disk failures and rebalances become unmanageable.
This is fair. It was a bug in their original calculator - the gp series don’t allow you to go beyond 16 TiB, only the most expensive io2s allow for sizes beyond that (and that’s only when using specific instances).
✅ A target network utilization of 33% is added to allow for cases when throughput increases and a need for rebalancing pops up.
This is also fair. Both cases are correlated - there is a greater chance of needing to rebalance when the workload spikes up.
Each EC2 instance has two types of network limits - one for its EBS drive connections (EC2<->EBS) and one for its regular connections (e.g EC2<->EC2). We will explore what the specific r4 instance limits are and whether that changes the calculation materially later.
These things give you the sense that the calculator is well thought through! And to a large degree, especially for a marketing tool, it really is.
😯 The compression ratio changed from 5 to 4.
Oh. That’s right! The calculator uses uncompressed writes as input but counts the compressed throughput when calculating the Kafka cost.
The Compression Gotcha 🙄
This is a subtle, very deceiving point.
The 5 GiB/s workload in our Before example represented 1024 MiB/s of actual throughput.
In our After example, the same 1 GiB/s input now represents an actual workload of 1280 MiB/s. (25% increase)
It was therefore an invalid comparison!
Before we fix the comparison - we should ask ourselves, why is the calculator made this way?
Unit Prices
It’s made this way because WarpStream charges on uncompressed traffic💡

This is a bit weird. I’m sending you 1 GiB of (compressed) data, you decompress it and charge me for the equivalent of 5 GiB of storage?
I guess you could justify it technically by acknowledging that WarpStream has to decompress the data and then compress in another format - that is extra work and there’s no guarantee what the end-result compression ratio will be.
Nevertheless - it is definitely not intuitive to the customer.
Thankfully, they explain why:

The TLDR:
🔮 predictable pricing - “we believe that your bill should not fluctuate based on which compression algorithm you choose to use in your client”
😇 incentives - “aligns incentives so that we (WarpStream) are encouraged to reduce your cloud infrastructure costs for the WarpStream BYOC product”
“this philosophy is also why we don't charge fees per Agent or per core.”
The latter point is a strong argument.
Managed service providers suffer from this dirty incentive where they earn more revenue if you’re inefficient with your workload. After all, that gives them more data to process and bill you with their high-margin marked-up prices!
They therefore benefit if you DON’T enable key cost-saving features like Fetch From Follower and Tiered Storage.
This benefits everybody down the chain - the hosted Kafka providers and AWS/GCP/Azure.
As Alex Gallego has pointed out - it’s part of the cloud business model - reselling more AWS infrastructure artificially inflates your revenue numbers, which is good when the market rewards growth at all costs.
By decoupling themselves from the direct underlying usage (compressed vs. not compressed) and avoiding other pricing models like per-Agent fees or core - WarpStream really does seem to align its incentives to ensure you spend the least on the cloud provider.
That’s really awesome. 🙌
The Change: 5→4 Compression
But still. It’s super confusing for a user of the calculator to associate the cost with the post-compression number.
Personally, I spent a lot of time focused on this calculator and I kept forgetting/getting confused while writing this article!
Everybody else I talked to fell for this gotcha while playing around with the calculator.
It’s interesting because the calculator apparently used to allow you to configure the compression ratio. It has commented-out code for a compression slider:

Anyway.
Lowering the compression ratio here penalizes Kafka disproportionately.
the same calculator input leaves:
the same cost for WarpStream (priced on the same unchanged uncompressed throughput)
a much higher one for Kafka (priced on the increased compressed throughput)
for each extra MiB, Kafka grows costs at a faster rate than WarpStream - i.e the higher the Kafka scale, the more WarpStream saves you.
This is because for every extra MiB/s of throughput, Kafka’s cost amplifies due to the extra storage needs, extra instance needs to accommodate the storage and the amplified inter-zone networking. Each extra MiB for Kafka:
results in 5x storage capacity - 3x (replication factor) + 2x (the 50% free space)
this results in the need for more instances, because an instance can only hold 16 TiB of disk.
incurs 4.6x its cost in inter-zone networking - 2x consumption, 2x from replication and 0.66x (2/3rds) from produce
The cost difference is therefore significant.
While we stayed on 5 GiB/s uncompressed and it resulted in 1 GiB/s - now it results in 1.25 GiB/s (25% more). That’s 240 MiB/s of extra throughput that’ll get amplified.
Amplification^2
What’s worse is that there are some outright blatant bugs and very questionable assumptions introduced that further amplify Kafka’s cost disproportionately. 😑
Before we go over the changes in detail, let’s skip forward a bit and illustrate the differences in granular detail:
how much the compression change alone changed prices
how much the other changes changed prices (assuming that compression didn’t change)
how much both changed prices combined
1️⃣ Compression Alone
Simply use the old calculator, but set a different input throughput to simulate the lower compression ratio.
Basically we’re trying to get the old calculator to give us the price for:
1 GiB/s of post-compression (simulating the old calculator set at 5 GiB/s)
1.25 GiB/s of post-compression (simulating the new calculator set at 5 GiB/s, but without the other changes)
So compression alone increased prices by 25%. That was predictable.
2️⃣ Other Changes Alone
Here we compare apples to apples - use the new calculator, but adjust the post-compression throughput to be the same:
The other changes alone increased prices by 64%. 😳
3️⃣ Combined
Now compare both, as if you simply opened the calculator the next day post-acquisition and entered in the same input:
Combined, they changed prices 105% up.
This amplification effect is more pronounced the more you increase the retention time:
Compression Conclusion
Changing the compression ratio allows the calculator to subtly compare Kafka more disfavorably, since it increases the dimension Kafka is billed on but keeps the WarpStream dimension the same
Kafka costs already grow at a faster rate than WarpStream, so the higher the Kafka throughput, the more WarpStream saves you.
There are some other changes that further amplify Kafka’s cost by 64%, without accounting for the compression. They somehow make Kafka’s costs grow even faster the more storage you add.
Combined with the compression gotcha, the Kafka price increases 105% from a base so high I think is 3.5x higher than what it should be.
Ok, enough with this rant about compression.
Let’s assume that in another life the compression slider was left in (or I’m a very astute user of the calculator that adjusted for the compression change).
Let’s compare apples to apples.
⚖️ Fair Comparison
To compare the Kafka cost of 1 GiB/s of post-compression throughput, we need to set 5 GiB/s in the old calculator and 4 GiB/s in the new one.
Here are the pricing changes after:
There are quite a few changes to dissect here. Let’s start in order of most questionable, descending.
💀 1. CPU Overkill
4XL
276 r4.4xlarge instances?!
These are HUGE instances. They’re 16 vCPU and 122 GiB RAM each.
At 1 GiB/s cluster-wide, you’re looking at each instance serving a measly… 3.7 MiB/s of producer traffic.
Even the smallest r4.large type can do that (10x cheaper). For production, perhaps a r4.xlarge would be a more fair fit (5x cheaper).
Regardless - the calculator said it assumed 10 MiBs per vCPU.
We now have 3.7 MiBs for 16 vCPUs? That’s just insane.
Two Hundred and Seventy-Six Nodes
A 276 Kafka node cluster is a non-starter. I don’t think Kafka would work at all with that many brokers. And if it did - it would be operationally impossible to manage.
But it’s true that once you have high throughput with a large retention period and you do not use Tiered Storage (admittedly it just recently became GA) - the disks will be the limiting factor. Limiting yourself to 16 TiB per node will require you to have 276 instances to host 4,536,000 GiB.
What a real production deployment would do, besides the low-hanging fruit of lowering the retention time or using tiered storage, is to deploy in JBOD (just a bunch of disks) mode with multiple EBS disks attached to the same broker.
That way, the broker could host up to e.g 64 TiB per node, and it would result in a more manageable 70 broker cluster size. (but admittedly will come with its own other problems too)
What about the networking capacity?
Earlier, we saw how the assumptions said that they target deploying at 33% network utilization. Can this be an explanation for the increased node size or larger node type?
A r4.4xlarge has a 3500 Mbps EBS link and “up to” 10 Gibps in general network. The calculator assumes 37.5 MiB/s of general network per vCPU - so with its 16 vCPUs it’d have 600 MiB/s of general network.
At 276 nodes, we have each node only write 11.1 MiB/s to EBS and serve around 22.2 MiB/s of network traffic. (produce, consume and replication)
Even if we scale down to the smallest r4.large instance type, we’d have 53.125 MiB/s to EBS and 75 MiB/s network. It would still be above the 33% requirement.
Given the code, the calculator never gets bottlenecked on the 33% network utilization when using a 7 day retention period (the default).
So we can forget about that being the explanation.
⚡️ 2. Network
The network cost for 1 GiB/s in a RF=3 setting across 3 availability zones is always the same. So why would it change?
Let’s first compute it ourselves, according to their assumptions:
Producer: 1 GiB/s is coming in, with 2/3 of it being cross-zone. That’s 682.666667 MiB/s of cross-zone produce traffic
Replication: With an RF of 3, 2 GiB/s gets replicated to other brokers. That’s all cross-zone.
Consumers: With a fanout of 3x, 3 GiB/s is consumed. 2/3 of that is cross-zone, so 2 GiB/s.
A total of ~4778.66667 MiB/s of cross-zone traffic is charged every second. The total charge-able traffic is therefore:
1 minute: 280 GiB (60 seconds)
1 hour: 16.41 TiB (60 minutes)
1 day: 393.75 TiB (24 hours)
1 month: 11812.50 TiB / 12,096,000 GiB (30 days)
AWS charges $0.02 per GiB of cross-zone traffic. ($0.01 on both the incoming and outgoing link)

Therefore for a month, we’d expect our inter-zone costs to be $241,920/m (12,096,000 GiB * $0.02/GiB).
This is exactly the same as the calculator’s old output of $241,920/m. It was correct.
How come it changed?
The Diff
Talk is cheap, Show me the code - Linus
Thankfully, the calculator code is in Javacript ran in the browser - so we can directly compare the diff.
Network Cost Changes

The way this code works is it calculates the cost of each produced GiB, by computing the price for each path (produce, consume and replication):
aws_cost_per_gib = 0.02
produce_cost = 2/3 * aws_cost_per_gib
replication_cost = aws_cost_per_gib * 2 * (RF-1)
consume_cost = 2/3 * aws_cost_per_gib # avoidable if Fetch From Follower is enabledThe calculator had already accounted for the RF of 3 by hardcoding `0.02 * 2`, but in the post-acquisition iteration it seems like a bug was introduced.
An extra `
* (RF-1)`is added, which double-calculates the replication cost.
The code essentially does `2 * (RF - 1) * 0.02`, resulting in `2 * 2 * 0.02`.
This double-counts the replication traffic and results in a new disproportionate (and completely inaccurate!) cost amplification for each extra MiB that Kafka gets.
That explains the extra network cost.
If we change our manual calculation above to inaccurately account for 4 GiBs of replication traffic (equivalent to an RF of 5), we get the same results.
Side-Note: KIP-392
The calculator has a Fetch From Follower option which omits the consume cost (which is always equal to the replication cost in this configuration) and provides a more realistic and optimal comparison between both systems.
Under an accurate calculation, this option would make Kafka significantly more competitive with WarpStream. But due to the replication cost bug, it doesn’t help here - it just resets you to the original correctly-computed networking price (with consumer traffic).
💾 3. Disk
If you notice carefully, there are two inconsistencies here:
total GiB increased by 25% - from 3.62M GiB to 4.53M GiB
total price increased by 56% - twice as much as the GiB
since GiB is charged at a fixed cost in AWS, we would expect the total price to increase by no more than 25%.
the only possible exception may be if the calculator used gp3’s unique ability to provision and pay for extra throughput capacity or IOPS, but that would be unnecessary since the devices are plenty capable of supporting 250 MiB/s at baseline and each broker is only receiving 12 MiB/s of post-replication write traffic (nothing).
So let’s dive into the code again:
💸 a) Pricing Change

The diff shows that the price changed from $0.08/GiB to $0.10/GiB - a 25% increase.
This explains why price grew faster than GiB.
But why did it change?
The stated reason in the comment says that MSK charges $0.1/GiB and that hardcoding it to $0.1 is simpler. 😁
That’s a bit dubious, because the calculator already has if branches for MSK cases and changing a single variable isn’t exactly “complex”.
The case the calculator code is making here is that simply using the most expensive price is simpler so that’s how you should compare the pricing. 👎
This also shows a contradiction - the original calculator didn’t actually account for gp2 prices ($0.10/GiB) despite saying so - it rather used the newer-generation gp3 prices ($0.08/GiB) and it knew full well it was the cheaper option - the price is in the code’s comments after all.
To reiterate - I see no reason why one would ever use gp2s in this scenario. The gp3s are cheaper and offer the same necessary performance. Even AWS recommends them.
All You Need is HDDs
Let’s not let this distract us though. Kafka was made to run on inexpensive HDDs.
There are certain performance-sensitive use cases which may warrant use of SSDs, but generally it is too cost-prohibitive to do it in the cloud unless you have tiered storage enabled and can afford to run with small disks.
The main reason you’d use SSDs in the cloud is to:
gain better latency for writes & historical reads
provision more IOPS, as cloud provider’s HDDs sometimes don’t give you enough and can be exhausted under high throughput / high partition cases.
In this particular example (and all others that I could come up with using the calculator), the Kafka deployment does NOT need SSDs. In fact - they’re massively overkill.
Let’s break down the cluster’s characteristics:
276 brokers
1 GiB/s total produce writes / 2 GiB/s replication writes
each broker therefore writes 11.1 MiB to its disk (3072 MiB / 276)
each broker has a 16.04 TiB EBS disk (4,536,000 provisioned GiB / 276)
Using EBS’ two HDD offerings, we see that both options provide ample throughput:
sc1 @ $0.015/GiB - gives you 192 MiB/s of base throughput per disk, burstable up to 250 MiB/s
st1 @ 0.045/GiB - gives you 500 MiB/s of base throughput per disk
The broker only needs 11.1 MiB/s…
Those EBS throughput numbers assume 1 MiB IOs, but keep in mind that both the OS batches pending write IOs due to the way Kafka writes to the pagecache (fsync off and deployed with ample memory) and EBS itself has a mechanism that merges sequential IOs into larger sizes.
sc1s are the cheapest offering and are therefore most likely good enough for this massively-overprovisioned case, but more performance-sensitive users may opt for st1.
AWS implies that st1s are more consistent performance-wise, delivering >90% of the expected performance 99% of the time in a year.
👉 That being said, if you were performance-sensitive, you wouldn’t be considering WarpStream in the first place, as S3 latencies are certainly going to be worse than anything an sc1 can give you.
So sc1 is the most fair comparison here.
Let’s compare the disk costs between all the EBS offerings:
$68k a month versus $453.6k a month.
So the calculator overestimated costs by 6.66x. Diabolical almost. 😈
A difference of $4.62M a year is quite a lot! That’s already 30% of the total (already-wrongly-inflated) Kafka cost for 1 GiB/s.
This $4.62M difference is in fact larger than what my computed total cluster fair price is! (more later)
🛢️ b) Provisioned GiB Increase
But that wasn’t enough. Total GiB increased from 3.62M GiB to 4.53M GiB.
Why would it start provisioning more space?
Let’s run the numbers: 👇
1 GiB/s of writes result in 3 GiB/s of data stored post-replication (RF=3)
with 7 days of retention, that’s:
1 minute: 180 GiB
1 hour: 10.55 TiB
1 day: 253.12 TiB
7 days: 1771.88 TiB
with 50% utilization (targetting 50% free space), that’s:
3543.76 TiB (1771.88 * 2)
✅ 3,628,810 GiB
This matches the previous value.
Why is it using 4,536,000 GiB now?
🔋 b.1) Utilization Percentage Change

💡 The target utilization percentage was changed from 50% to 40%.
This is inconsistent with the assumptions pubilshed on the same page - they still say 50%.
Having some free space for Kafka is a good call, as you need:
time to respond in case the write throughput suddenly increases
time to reassign partitions out of brokers
During any single partition reassignment, data for that partition is replicated more times than needed in that intermediate state (up to 2x RF)
Without Tiered Storage, these reassignments can take a long time for large partitions
The only question is what that threshold should be.
I alluded to this earlier - I think that 50% is too much free space to begin with, especially at large sizes. (note that the calculator is designed to showcase large sizes - the default is 100 MiB/s after all)
Now the threshold has moved down to 40%. It leaves you with 60% free space.
That means that every Kafka broker will use at most 6.4/16 TiB. That leaves 9.6 TiB of unused expensive SSD space.
This is evidently overkill, as the brokers only get 11.1 MiB/s of write traffic under this deployment. If the throughput doubles, you’d need 10.5 days to fill that free 9.6 TiB.
💡 Even if that throughput unexpectedly tripled to 36 MiB/s, you would need more than three days (3.24) of non-stop sustained triple throughput to fill the extra free 9.6 TiB with data.
This already skews the cost calculation a large amount, because for each 1 TiB of data written, you will now provision 2.5TiB (instead of the previous 2TiB, which was high to begin with).
Remember also that producer writes are amplified by 3x themselves, due to the replication factor:
💡 1 GiB/s of producer traffic results in:
3 GiB/s of data written to disk
7.5 GiB disk capacity provisioned to accommodate it.
And that per-GiB cost is 6.66x higher than what it should be…
☝️ b.2) Utilization’s Effect on Instance Count
It doesn’t end there.
Kafka frequently becomes bottlenecked on storage when configured with a reasonable retention time (e.g 7 days) and without Tiered Storage (as is the case here).
Because every broker can only host 16 TiB of data, you’re forced to provision more nodes ($$$) in order to accomodate the extra free capacity you want to have.
Not to mention that these nodes are already 5-10x overprovisioned by their types (4xlarge).
Ideally, you would just deploy Tiered Storage and avoid this need to scale compute in order to catch up to storage requirements.
If you can’t, then you’d look into JBOD to be able to host more storage per node and accept the extra operational burden that comes from a lot of state per broker.
In truth, right-sizing Kafka and modelling the extra disk space is a complex topic. I started a discussion on the /r/ApacheKafka subreddit and while I got some answers, we’ve reached a point where people answer with “just use WarpStream”.
Changes Conclusion
That was a lot to go over…
In conclusion to this section, if you ignore the compression gotcha - the other changes to the calculator increased Kafka’s cost by 64%.
They were:
a glaring bug resulted in the expensive replication network costs being doubled
disks price was increased 25% from 0.08 to 0.1 “for simplicity”
the disk free space requirement was increased from 50% to 60% without mention
it deployed a gazillion instances to handle the extra storage requirements - 276 nodes
the 16 TiB limit introduction bumped the node size to 222 and the extra 10% free space bumped it to 277
Combine this with:
the compression gotcha
the 6.66x disk cost overestimation
ignoring tiered storage and not defaulting to fetch from follower enabled
the explicit promises that the calculator goes out of its way to model realistic parameters and NOT skew the results in favor of WarpStream
And you’ve got yourself a pretty deceiving comparison calculator that skews the results massively.
The Real Price
It’s easy to be a hater. A productive discussion should propose an alternative.
The way I ran the same numbers, I got the following:
222 r4.xlarge @ $43,136/m - 5x less cost than WarpStream’s Calculator
222 16TiB EBS sc1s with a total 3,637,248 GiB disk capacity costing just $54,432 - 8.33x less cost.
$241,920/m inter-AZ network costs - 1.42x less than WarpStream’s calculator, and equal to their previous correct value
Ideally, I would run Tiered Storage and Fetch from Follower to reduce the Kafka cost dramatically. But I kept within the constraints to make it a fair comparison.
If we are to run with those optimizations, it would be:
13 r4.4xlarge brokers
13 1,663 GiB gp2s
(it would be cheaper to use gp3s, but the tool I used doesn’t have full support)
And it’d cost you just $167,151 a month - 6x less than what WarpStream would have you believe Kafka costs. Six times less.
You may add a few extra brokers if you’d like to have extra network capacity / buffer, but it wouldn’t change the cost significantly.
Comparing All AWS Costs
Optimizing Kafka Costs
This article is long enough, but let me summarize how one can optimize their Apache Kafka cluster’s costs in a few words:
KIP-392 (Fetch From Follower) reduces Kafka costs in the cloud massively by ensuring that the consumers don’t rack up cross-AZ networking costs when consuming
in a cluster with RF=3, removing the costs associated with a consumer fanout of 3 costs is equivalent to removing replication. (what WarpStream innovates with)
the higher the consumer fanout, the higher the savings you get by enabling it
KIP-405 (Tiered Storage) does a lot more than just reducing your costs, but it does reduce your costs a ton.
the disk costs are reduced by approximately 3x
the instance costs are reduced significantly too. in our example, it reduced instance costs 4x. This is because the storage capabilities become a bottleneck and require you to deploy more brokers solely so that they can store the data.
That’s what exists today and is production-ready.
What else can be done in the future?
[FUTURE KIP] - a Produce to Local Leader KIP, similar to KIP-392, can be introduced to eliminate producer inter-AZ network costs for topics that do not have keys.
there is no fundamental reason that a topic without ordering guarantees needs to produce to a specific partition - why not just choose the broker in the closest zone?
if all of your traffic is unkeyed, then this can further reduce Kafka’s network cost by 25%.
it sounds like a change that wouldn’t be too complicated, maybe even achievable today in a hacky way through the Producer’s partitioner.
[WISH] - maybe the community can get together and try to replicate a WarpStream-like direct-to-S3 feature inside Kafka, perhaps a different kind of topic. I have heard rumours that some people are working on this, but I’m not sure how reliable said rumours are.
If these two things come together… Apache Kafka would be incredibly hard to beat cost-wise.
Is Kafka Really That Bad?
Smear Campaign
The WarpStream team has been known to talk against Kafka.
Apart from catchy names, their blog posts were always full of interesting cutting-edge insights of the latest best practices in the industry, like deterministic simulation testing with Antithesis, Dealing with rejection (in distributed systems), the Case for Shared Storage.
Despite that, a lot of the blog was just focused on bashing Kafka - The Original Sin of Cloud Infrastructure, Cloud Disks are (Really!) Expensive, Tiered Storage Won’t Fix Kafka - disparaging how overly expensive and complex Kafka seems to be, compared to their solution.
I find the blogs have a lot of good information, some half-truths and then some extreme exaggerations that makes little sense for the experienced engineer - but it sounds believeable because the build up to it was great. My guess is also that most people don’t have the bandwidth or experience to verify every claim.
Two simple examples:
Case for Shared Storage - compares WarpStream to a Kafka cluster where a single partition can burst up to 500 MiB/s
Tiered Storage Won’t Fix Kafka - inaccurately states that Tiered Storage implementations require you to read the full segment before any reads can be served, or that they need to write to disk and therefore compete for IOPS with client workloads;
then focuses on how it isn’t a fix because it doesn’t reduce the networking cost while not acknowledging the massive reduction in storage and by extension instance costs it provides.

Tiered Storage actually works great in practice and I have operational expertise behind thousands of clusters at Confluent to prove it. The improvements we saw after we deployed it were massive.
WarpStream basically came in the industry, provided a good solution, bashed Kafka, and got acquired for a hefty sum by the Kafka company after 13 months.
Everything they said has a grain of truth, but like any good marketing - a large part isn’t true.
Debunking “Truths”
As the title said, this is the brutal truth about cost calculators. Let me present a real kicker to you:
WarpStream is NOT Cheaper than Apache Kafka 🔥
WarpStream is actually not cheaper than self-hosting Apache Kafka in two of the three public clouds.
That’s right. Despite what their marketing says, when I run the numbers, I find that self-hosting Apache Kafka is cheaper than WarpStream in both GCP and Azure.
And where WarpStream is cheaper than Kafka (in AWS), it is only by 32%, and the sole reason for that is AWS’ absurd network costs.
That’s not quite the “10x cheaper” they claim.
Note also that if we account for AWS discounts (also called PPAs), one could realistically expect their Kafka on AWS to be the same price or cheaper than WarpStream.
Cloud prices, especially networking, are very negotiable depending on how much you spend. And if you’re inclined to run Kafka at scale yourself (or BYOC), chances are you already have a good amount of spend on the cloud.
Anyway, I digress.
Here are the numbers to back my claim:
Input
The input is the same as the one we used in this article:
Produce Pre-Compression: 4 GiB/s
Produce Post-Compression: 1 GiB/s
Consume: 3 GiB/s
Retention: 7 days
Kafka uses KIP-392 and KIP-405
Output
And by the way - this public pricing was most likely never their actual production pricing. It was the minimum.
WarpStream has pricing tiers. There is only one tier that uses the public usage-based that the calculator uses pricing. Said tier coincidentally has no SLA - so it’s unusable in production.

The others are most certainly higher, since they have no public numbers but just a “Contact Us”.
So no - WarpStream is not cheaper than Kafka.
It’s simpler. But not cheaper.
Before declaring it better, it’s important we keep in mind that this is still a young immature infrastructure project. It just a year and a half old!
It doesn’t matter how talented the engineers working on it are nor how many customers they have - any infrastructure software that’s 16 months old is immature by definition.
Kafka was in that stage for a very long time itself too, despite having top talent working on it and being used in production by big companies the likes of LinkedIn at the earliest stages.
Poor Kafka 😢
It’s true - Kafka isn’t perfect.
There are products like Confluent, Pulsar and RedPanda that work hard to improve upon the obvious gaps in the open source project.
Kafka is old too. Jay reportedly started writing it as early as 2008, and it was open sourced in 2011.
But old != outdated.
PostgreSQL was released in the 80s (1989) and it is still everybody’s go-to database in 2024! (despite the massive competition)
Kafka still has a very active community, perhaps its most diverse one ever so far, and is one of the most visited Apache projects.
Why is nobody defending Kafka?
Kafka is an open-source project with a diverse community of competing interests (contributors’ employers).
It can’t defend itself, which is a negative.
We as a community should do better in pushing back against claims without proper data to back them up.
I should have done better.
So I am making it up with this article.
I see it as my duty. My brand is based on Apache Kafka after all.
On the flip side? Kafka also can’t hype itself up with marketing claims that aren’t true.
This sounds like a negative but is perhaps a plus… at least you can trust Kafka.
![I was ashamed of myself when is realized life was a costume party........" -Franz Kafka [512x640] : r/QuotesPorn](https://substackcdn.com/image/fetch/$s_!qpmf!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb8922739-0943-4162-9cff-a8c30ea372eb_512x640.jpeg "I was ashamed of myself when is realized life was a costume party........\" -Franz Kafka [512x640] : r/QuotesPorn")
Thanks for reading.
~Stan
Liked this article?
🤩 Announcement: AKalculator
I spent the last two months coding up an in-depth Apache Kafka deployment calculator, and today I’m releasing it.
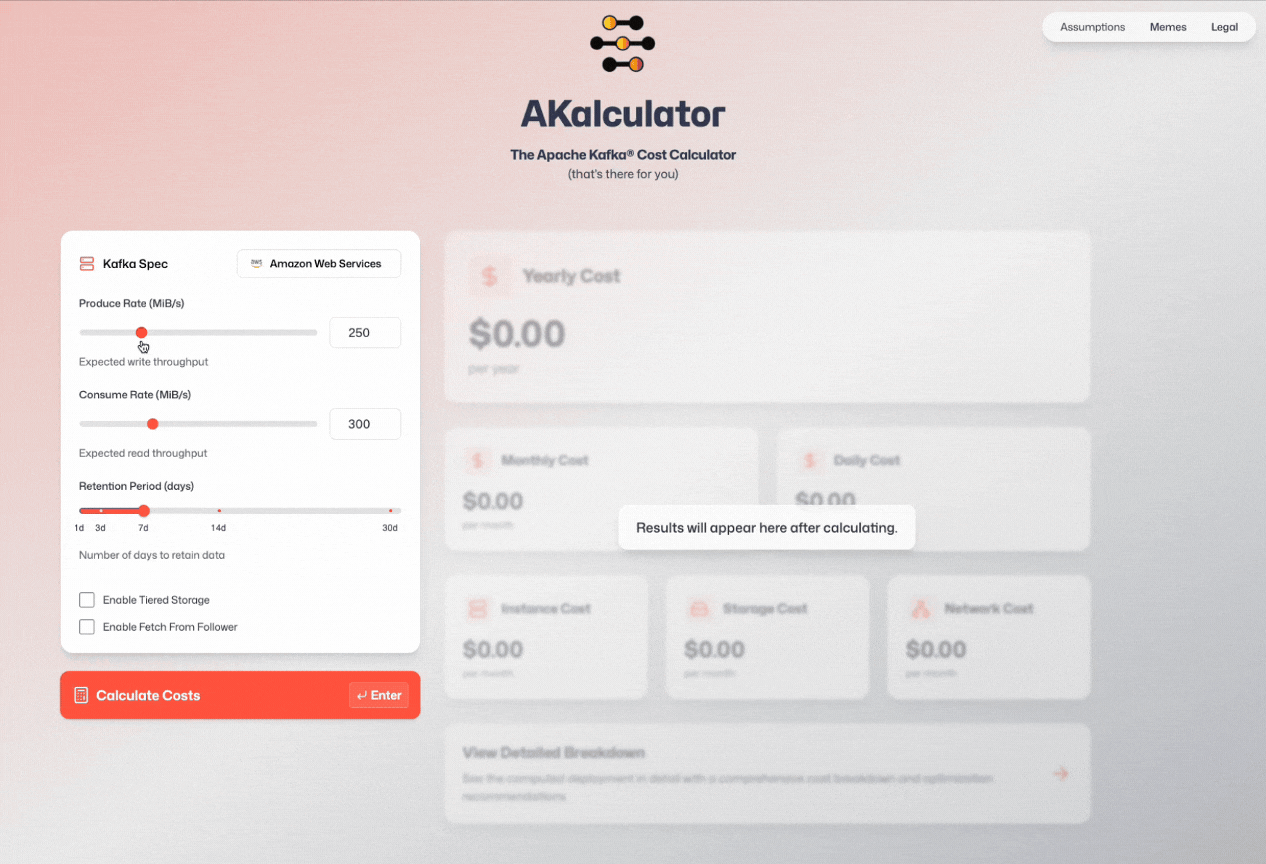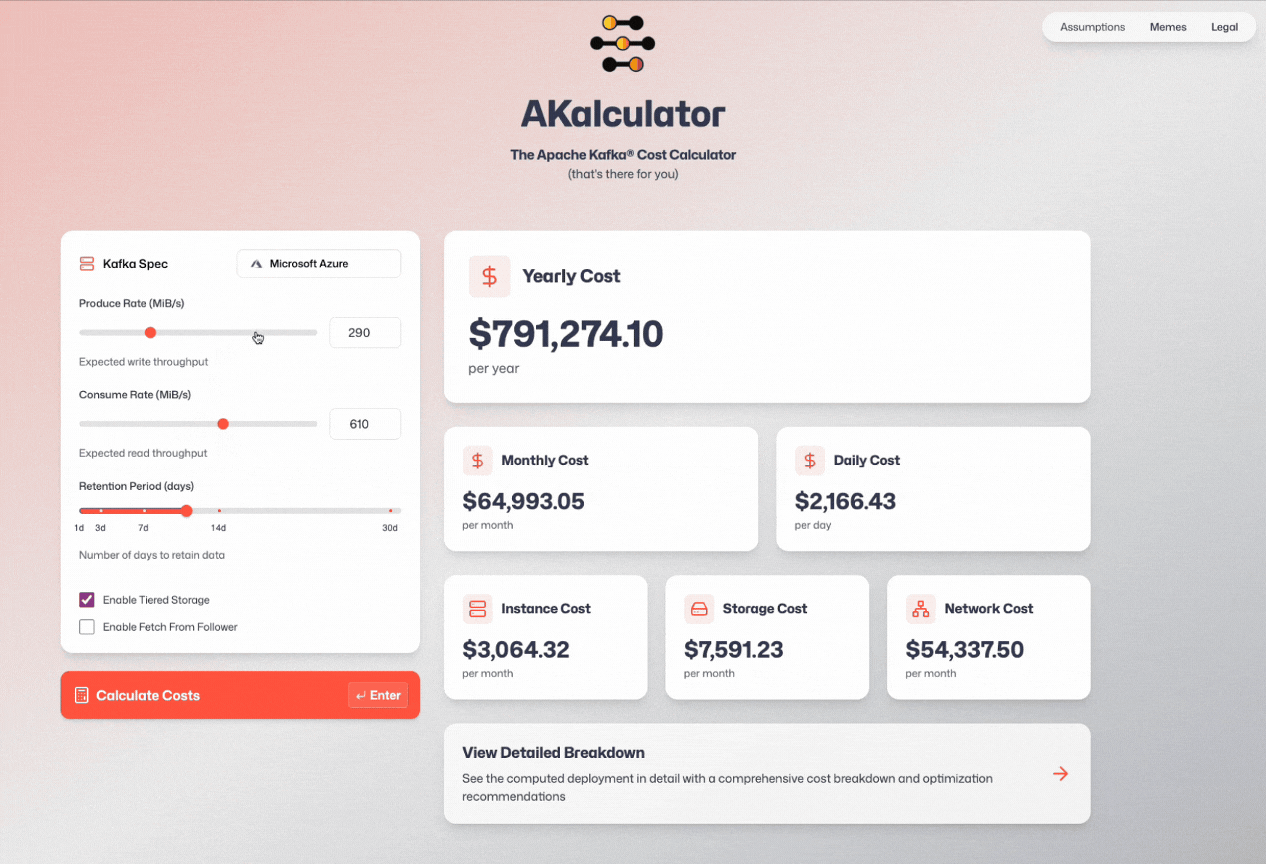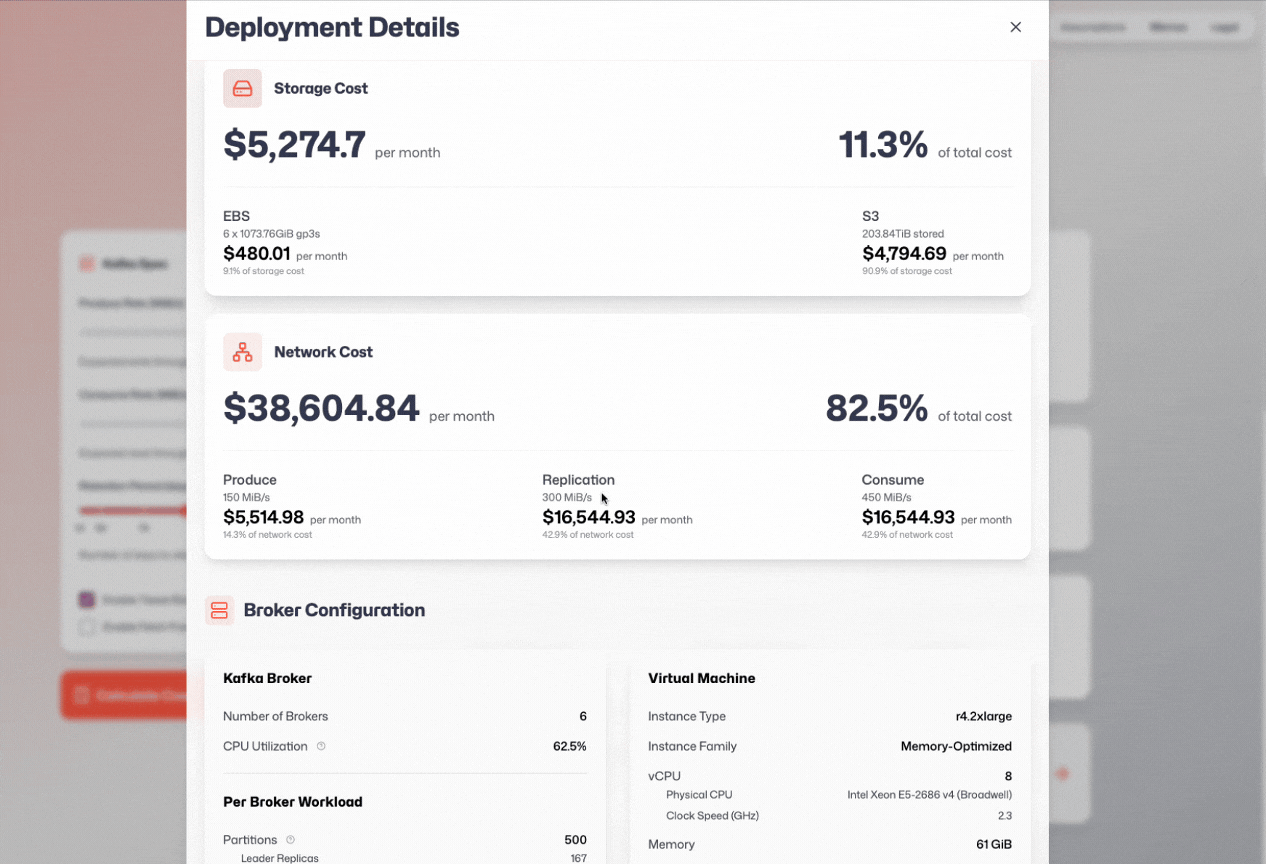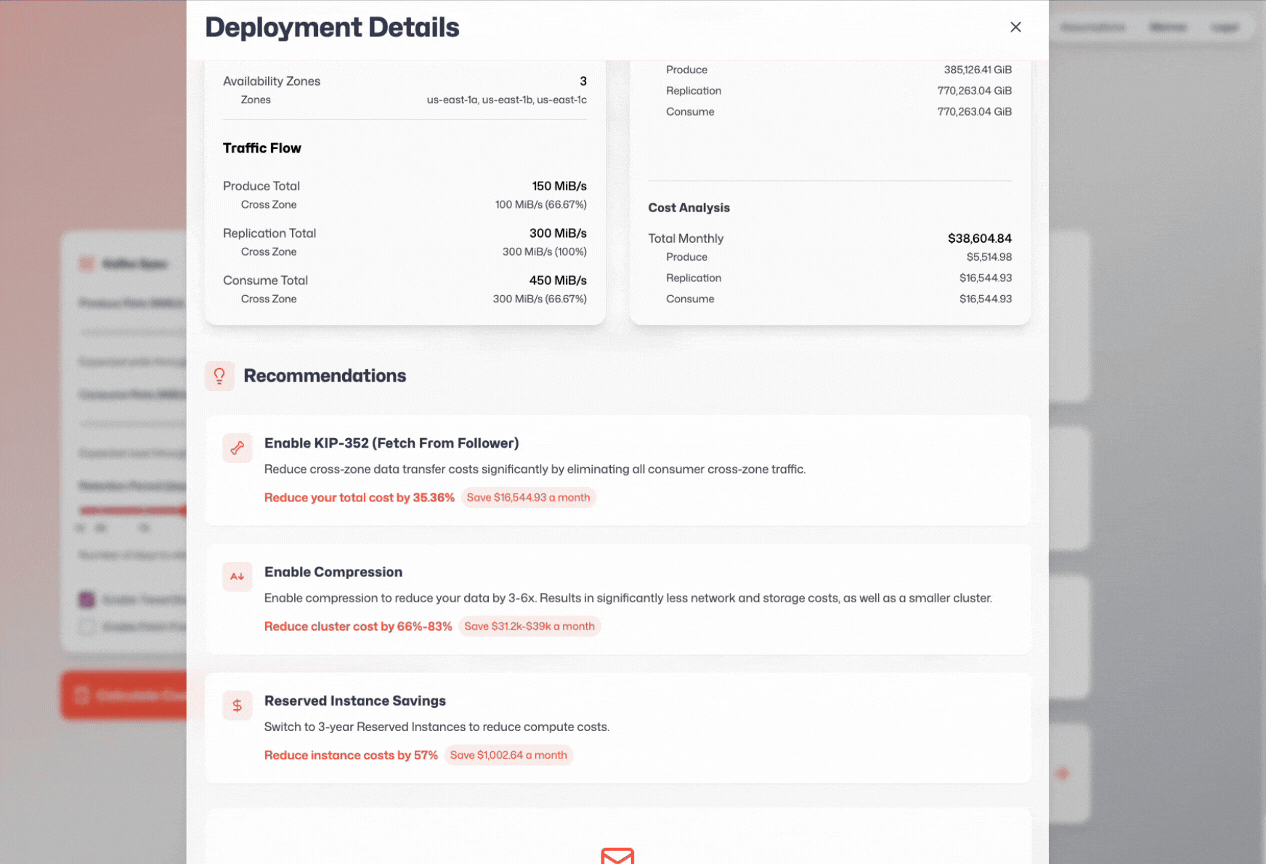
Admittedly, it’s not open source - so you’ll have to trust my implementation.
The good news is that I’m incentivized to show the lowest possible cost for Apache Kafka that’s also realistic, since my clients would be disappointed if I sold them a false dream.
There’s also a Featurebase board where you’re encouraged to argue with me as much as possible. I’m not saying the calculator is perfect yet - but discussion will help reach a better state.
I believe it’s much more accurate than the WarpStream one, or any other calculator provided by a Kafka competitor.
The vendor is incentivized to make Kafka seem more expensive and more complex than it is, in order to increase its relative value proposition.
Such a product is bound to suffer from the same fundamental misalignment in incentives.
This one isn’t.
Check it out here:
👉 AKalculator
Disclaimers
To end this on a happier note, I want to add a bit of a disclaimer at the end.
I worked in Confluent for 6 years. Some people may see it as a bit of a backstab to speak out against a company they acquired.
I wanted to write out my thoughts in detail so there aren’t any questions about intention, malice, agenda, etc.
• I have only good things to say about Confluent. The company was always transparent, the founders are great people and the culture in there was great.
• I worked with talented, honest co-workers and friends there.
• I have equally published multiple posts praising Confluent's product and the company. And will continue to when the opportunity arises.
• I see WarpStream and Confluent as separate, at least in the actions they’ve taken and the culture they've shown.
• I do think WarpStream has a very strong team and an amazing product, it’s a true testament of excellence what they managed to build.
• I think what WarpStream did in marketing was not right with relation to the open source Apache Kafka project.
I therefore believe a call out and a bit of parody in response is therefore fair game.
I don’t mean to build my brand off drama and controversy. I’ll be going back to my regularly-scheduled programming right after this post.
I realize the initial disclaimers on my newsletters were too vague regarding my intention, so I have updated them there too.
I don’t have a bone to pick. I realize other companies make similar non-truthful claims in their marketing too. And I think they should be called out too. 👮♂️
Especially if it goes too far.
I tried very hard to keep everything objective and backed by data. I have only used data I've publicly observed and expressed my opinion based on it.
I don't think I should censor myself simply and cherry-pick who I call out simply because I have some indirect history with them.
If there are any strict errors - please tell me, I will correct them and apologize.
I would prefer to say the truth. I would say it to a friend too.
If you don’t agree, then perhaps we can agree to disagree. 🤷♂️
You’re free to unfollow me and hold your own views. ✌️
It’s just some pixels of a post on the internet after all.
But I hold no negativity. Hopefully you don’t either. 😇
Apache®, Apache Kafka®, Kafka, and the Kafka logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Appendix
As promised, a reference-able set of facts:
to begin with, WarpStream’s Kafka cost calculator inaccurately inflates Kafka costs by 3.5x:
using instances that are 5x larger cost-wise than what they should be - a 16 vCPU / 122 GiB r4.4xlarge VM to handle 3.7 MiB/s of producer traffic
using 4x more expensive SSDs rather than HDDs
using too much spare disk capacity for large deployments, which racks up said expensive storage cost and causes you to deploy more instances
WarpStream’s price post-acquisition increased by 2.2x, but its cost savings percentage against Kafka changed by just -1%.
The calculator’s compression ratio changed, and due to the way the pricing works - this increases Kafka’s costs by 25% while keeping WarpStream’s costs the same, for the same calculator input.
The calculator unintuitively gives you pre-compression input, which allows it to subtly change the underlying values to higher ones. This compares Kafka more disfavorably, since it increases the dimension Kafka is billed on but keeps the WarpStream dimension the same.
Kafka costs already grow at a faster rate than WarpStream, so the higher the Kafka throughput, the more WarpStream saves you.
This pre-compression thing is a gotcha that I and everybody else I talked to fell for - it’s just easy to see a big throughput number and assume that’s what you’re comparing against. “5 GiB/s for so cheap?” (when in fact it’s 1 GiB/s)
The calculator was then further changed to deploy 3x as many instances, account for 2x the replication networking cost and charge 2x more for storage. These were done by:
introducing a blatant bug to 2x the replication network cost (literallly a `* 2` in the code)
deploy 10% more free disk capacity without updating the documented assumptions which still reference the old number
this has the side-effect of deploying more expensive instances
increasing the EBS storage costs by 25% by hardcoding a higher volume price, quoted “for simplicity”
the end result is that:
storage cost is overestimated by 8.33x
if we are to count enabling tiered storage, the cost drop even more - by 24x
the instance cost is overestimated by 5x
the inter-AZ network cost is overestimated by 1.42x due to a blatant bug
All the while, WarpStream claimed in multiple places that their objective is to NOT skew the results in favor of WarpStream, that the calculator allegedly makes “a ton” of assumptions in Kafka’s favor and goes out of its way to model realistic parameters.
my calculation using a fair comparison to their calculator (an unoptimized deployment without KIP-392 or KIP-405) gives a 3x lower cost of $4.06 million per year versus their $12.12 million per year for a 1 GiB/s deployment.
222 r4.xlarge @ $43,136/m - 5x less cost than WarpStream’s Calculator
222 16TiB EBS sc1s with a total 3,637,248 GiB disk capacity costing just $54,432 - 8.33x less cost.
$241,920/m inter-AZ network costs - 1.42x less than WarpStream’s calculator, and equal to their previous correct value
my calculation using an optimized Kafka deployment would give you a 6x lower Kafka cost of just $2 million a year for the same 1 GiB/s deployment.
As of November 2024 prices, WarpStream is NOT cheaper than Kafka in two of the three clouds (table)
AWS
Kafka: $180k/month
WarpStream: $122k/month
GCP
Kafka: $93k/month
WarpStream: $118k/month
Azure
Kafka: $29k/month
This is insanely cheap, but it’s not a typo. Azure doesn’t charge on cross-zone networking fees, and those are the main cost driver of an optimized Kafka deployment.
WarpStream: $126k/month
Note that these don’t account for cloud cost discounts, which will likely be a factor if you’re self-hosting (or BYOC-hosting) significant infra in your cloud account.
Thanks a lot for the calculator and for sharing such a good analysis!
It would be great to get some comments from the WarpStream and see open discussion around the cost calculation.
Thanks, Stan, for all the effort you’ve put into creating the AKalculator. It seems an excellent tool, offering a vendor-neutral perspective on the cost of Kafka deployments. Although this is an early version, I’m confident it will prove really useful and impactful across the Kafka community.
Having followed your journey for nearly two years, I really admire and appreciate your transparency and fairness. I really believe this tool reflects those qualities and will help reorient conversations around Kafka deployment in a cost-effective way. Great work! 🙌