

Why Was Apache Kafka Created?
The story behind how LinkedIn created Apache Kafka


Reading Time: 13 minutes
EDIT: This reached first page on Hacker News and spurred some good discussion. Check it out here:
Intro - the Integration Problem
We talk all the time about what Kafka is, but not so much about why it is the way it is.
What better way than to dive into the original motivation for creating Kafka?
Circa 2012, LinkedIn’s original intention with Kafka was to solve a data integration problem.
LinkedIn used site activity data (e.g. someone liked this, someone posted this)1 for many things - tracking fraud/abuse, matching jobs to users, training ML models, basic features of the website (e.g who viewed your profile, the newsfeed), warehouse ingestion for offline analysis/reporting and etc.
The big takeaway is that many of these activity data feeds are not simply used for reporting, they’re a dependency to the website’s core functionality.
As such, they require very robust infrastructure.
Their old infrastructure was not robust.
It mainly consisted of two pipelines:
The Batch Pipeline
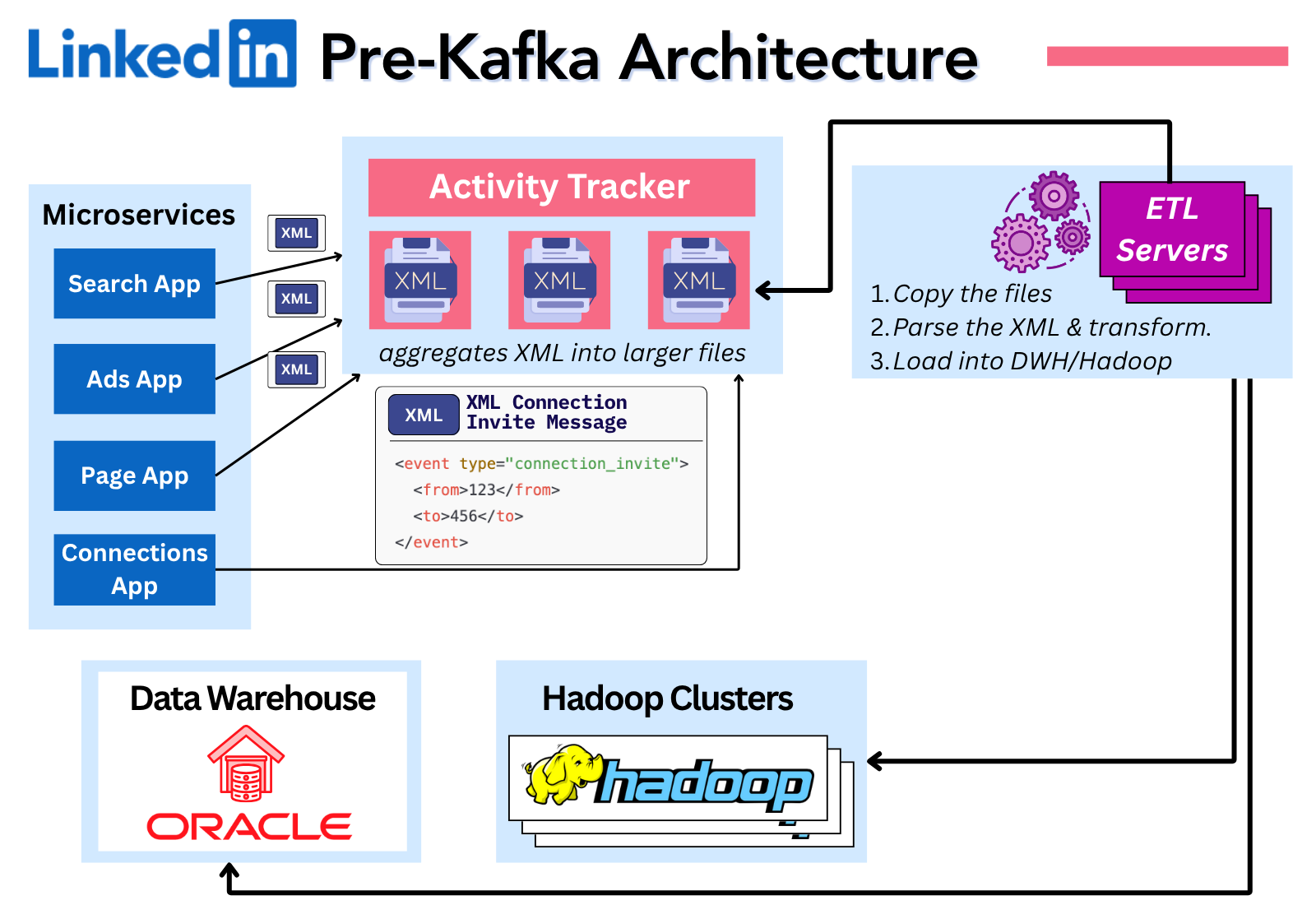
One was an hourly batch-oriented system designed purely to load data into a data warehouse.
Applications would directly publish XML messages of the events (e.g profile view) to an HTTP server. The system would then write these to aggregate files, copy them to ETL servers, parse & transform the XML and finally load it into the warehouse infrastructure consisting of a relational Oracle database and Hadoop clusters.
The Real-Time Pipeline
They used a separate more real-time pipeline for observability. It contained regular server metrics (CPU, errors, etc.), structured logs and distributed tracing events, all flowing to Zenoss.
It was a cumbersome manual process to add new metrics there. This pipeline’s data was not available anywhere else besides Zenoss, so it couldn’t be freely processed or joined with other data.
💥 The Problems
There were a few commonalities between both of these pipelines:
manual work - both systems required a lot of manual maintenance, both to keep the lights on and add new data to.
large backlogs - both systems had large work backlogs of missing data that needed to be added by the resource-constrained central teams responsible for them.
no integration - both of these systems were effectively point-to-point data pipelines that delivered data to a single destination with no integration between them or other systems.
Along the line, LinkedIn figured out that they gained massive value from the simple act of integration - joining previously-siloed data together. Just getting data into Hadoop would unlock new features for them.
As such, the demand for more pipelines to move data to Hadoop grew. But data coverage wasn’t there - only a very small percentage of data was available in Hadoop.
The current way was unsustainable - the pipeline team would never be able to catch up with their ever-growing backlog as more teams realized the value and demanded more features.
There were too many problems - both individual within the pipeline and fundamental throughout the architecture - that made it impossible to scale:
Schema Parsing: there were hundreds of XML schemas. XML did not map to the downstream2 systems (e.g. Hadoop), so it required custom parsing and mapping.
This was time consuming, error prone and computationally expensive - they would often fail and were hard to test with production releases. This then led to delays in adding new types of activity data, which forced them to do hacks like shoe-horning new data into already-existing inappropriate types in order to avoid extra work but ship on time.
Brittle: The pipeline(s) were critical, because any problem in it would break the downstream system (i.e website feature). Running fancy algorithms on bad data simply produced more bad data.
Reliability had to be prioritized.
Schema Evolution: adding/removing fields from the schemas without breaking downstream systems in the pipeline was hard.
The app generating the data would own the XML format - testing and being aware of all downstream uses was difficult for them, especially due to the asynchronous nature of the pipeline.
There wasn’t good communication between teams either, so sometimes the schema would change unexpectedly.3
Lag: it was impossible to inspect the activity metrics in real time. They would only be available hours later (via the batch process).
This led to a long lag time in understanding and resolving problems with the website.
Separation of Data: the fact that operational server metrics can’t be joined with the activity data was problematic - it further prevented them from correlating, detecting and understanding problems (e.g. decrease in page views can’t always be seen in server CPU metrics)
No Deep Operational Metrics Analysis: can’t run long-form longitudinal queries on the operational metrics because they’re only present in a real-time system that doesn’t support such queries.
Single Destination: the use cases for the activity data were growing by the day. But the clean data was solely present in the warehouse. Even if it had 100% data coverage, it wasn’t enough for the data to just be there. It had to go to other destinations too.
What Did They Need?
Reading these problems, LinkedIn’s requirements are pretty clear.
They needed to have robust pipeline (1/7) infrastructure (i.e a standardized, well-maintained API). This pipeline had to be scalable (2/7).
They needed to handle schemas (3/7) properly - commit to a backwards-compatible contract.
They needed the system to handle high fan-out (4/7) - the activity data, for example, needed to go to a lot of destinations.
They needed it to be real-time (5/7) - measured in seconds, not hours.
They needed plug-and-play integration capabilities (6/7). Ideally new sources/sinks would be very easy to load, without any manual work. For this to work, they needed structured schemas (the 3/7) with clean data (6/7), so no extra processing would be required.
And they needed to switch the ownership (7/7) of some of this work, because the two small teams handling the pipelines would have never caught up on their large backlogs while the rest of the organization kept coming up with new use cases.
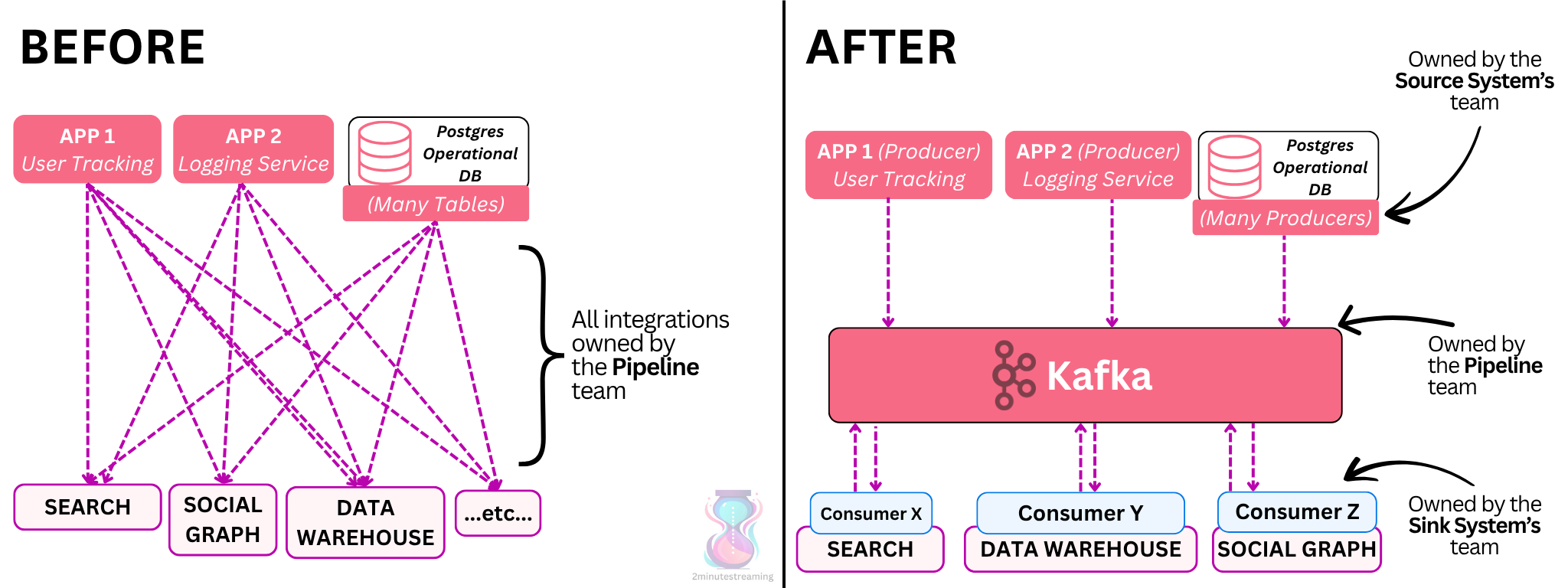
PS: While evaluating solutions, they figured out that the system had to support data backlogs - i.e decouple writers from readers (8/8). Some systems they tested (ActiveMQ) would collapse in performance when readers fell behind and a significant data backlog accumulated.
Enter - Kafka 🔥
They created Apache Kafka. This solved for 5/8 of the problems:
Robustness (1/7) - being a distributed system with built-in replication, failover and durability guarantees meant single machine hiccups would not disrupt the pipelines
Scalability (2/7) - the distributed nature and sharding of topics via partitions made it horizontally scalable on commodity hardware
High read fan-out (4/7) - the lock-free design of the Log data structure made high-scale reading trivial
Real-time (5/7) - the system was real-time, although funnily initially average latency of their large multi-cluster pipeline was 10 seconds. Nowadays this’d be a lot lower.
Decouple writers from readers (8/8)- the fact that the data was buffered to disk by design allowed them to set longer retention and not tie the retention to whether the message was consumed or not. This meant slow readers would never impact the system.
The other three problems were schemas, data integration and ownership.
Let’s dive into them, because they’re pretty interesting.
1. Schemas
They moved from XML to Apache Avro as both the schema and serialization language for all the activity data records, as well as downstream in Hadoop.
This led to significantly less data size - Avro messages were 7x smaller than XML. They additionally compressed them 3x down later when producing to Kafka.
They developed what seems like the precursor to Confluent’s Schema Registry: a service to serve as the source of truth for the schema in a Kafka topic, as well as maintain a history of all schema versions ever associated with the topic.
Kafka messages carried an id to refer to the exact schema version it was written with. This versioning made it impossible to break deserialization of messages, because you could always know the right schema to read a message with.4
This was a much needed improvement, but it wasn’t everything they needed.
While messages were individually understandable, Hadoop applications could still be broken by toying with the schema - e.g. removing a field in the record they needed to use. They generally expected a single schema to describe a data set.5
To solve this backwards compatibility issue, LinkedIn developed a compatibility model to programmatically check schema changes for backwards compatibility against existing production schemas. The model only allowed changes that maintained compatibility with historical data - something that sounds just like schema registry’s `BACKWARD` compatibility level.6
2. Plug & Play Integration
To make new data very easy to integrate without any extra manual work, you need to settle on a single schema between the upstream and downstream system.
Having even slight differences means you’ll always have to translate them between systems - i.e., an extra JIRA ticket for somebody to manually write, test & deploy code to transform the data into whatever the downstream system’s requirements.
But if the schema is the same, then that work doesn’t exist.
Ideally, you could then fully automate data offload to sinks because there’s no extra work to do besides writing to the particular sink system’s API.
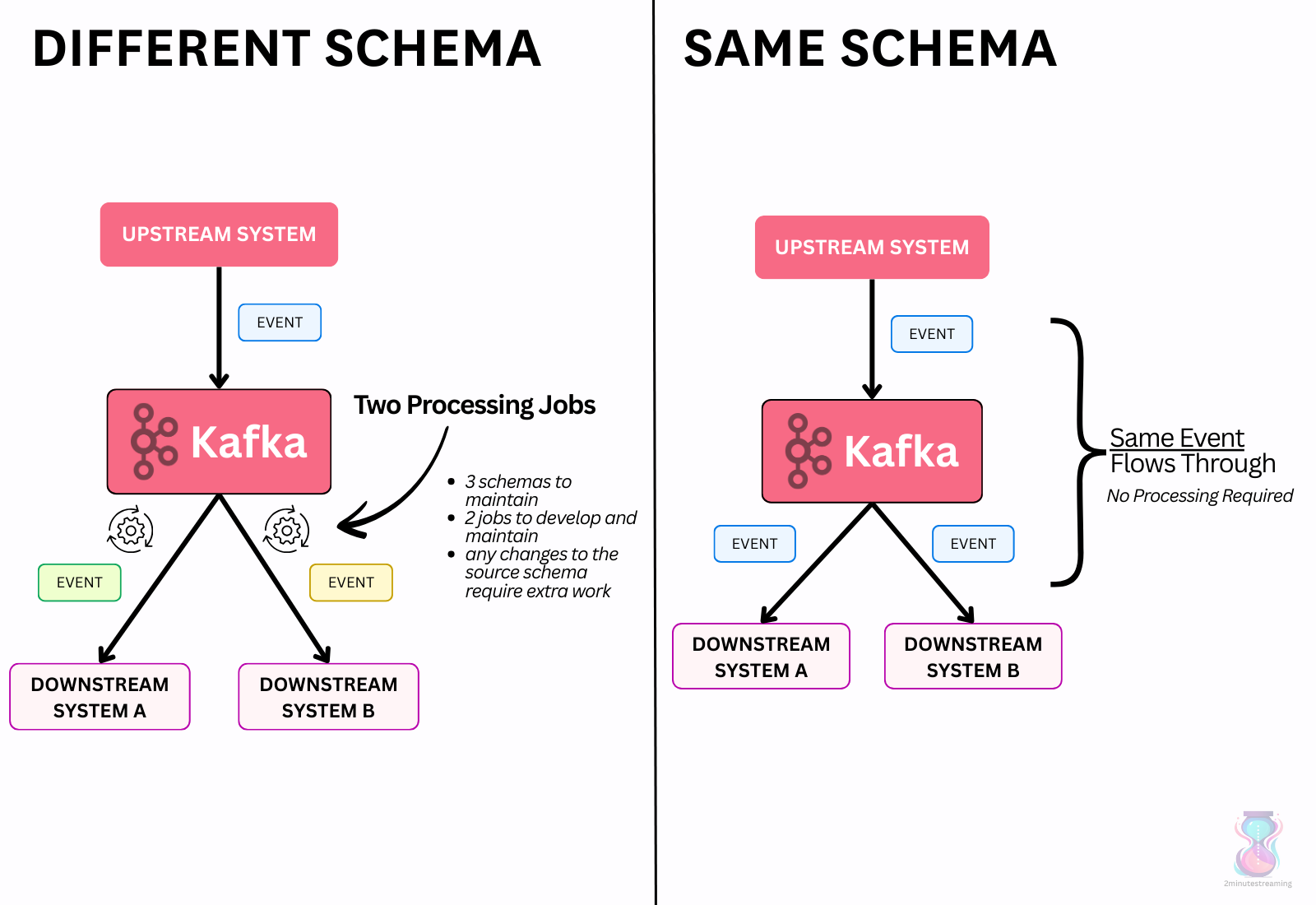
Another big problem with the different schema approach was the time at which problems would surface. Hadoop used a Schema on Read model, where data would be stored in files, unstructured7, and the structure would only be defined within each script that reads the files. This meant that things would break much later, at query time, not at the time of ingestion.
Traditionally, at the time, the data warehouse was the only location with a clean version of the data. The dirty, unstructured data would land in Hadoop, and then get cleansed/curated through various scripts (if they didn’t break).
Access to such clean & complete data was of utmost importance to any data-centric company, so having it locked up in the warehouse didn’t scale to meet the organization’s needs. Not to mention it only arrived in the warehouse after hours of delay - very problematic for anybody who wants to access it sooner.
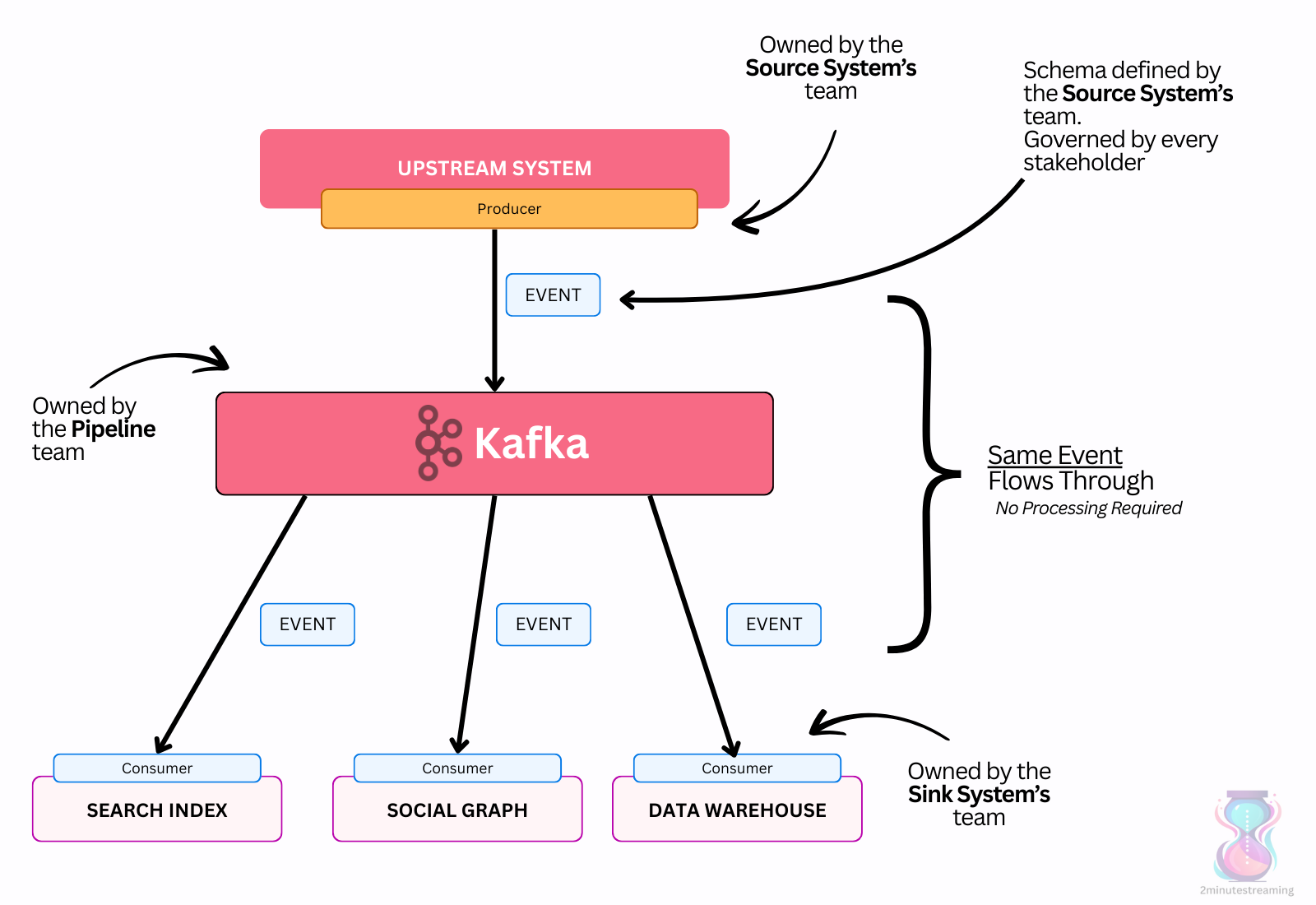
The solution was very straightforward - “simply” move the clean data upstream to a real-time source. Clean it as it lands into Kafka - i.e adopt a Schema on Write model.
This not only allows plug and play integration with the warehouse (e.g creating a new table from a new topic is a piece of cake), but also makes it available for other types of consumers - be it real-time or batch.
Similarly, schema changes like adding a new field could be automatically handled.
That’s exactly what LinkedIn did - define a single uniform schema with the canonical, cleansed format of the particular message. But this required organizational change to execute:
3. Ownership and Governance
Previously, it was the pipeline team’s responsibility to match the schema to the downstream system. LinkedIn needed to move this ownership away from them if they wanted to ever get to 100% data coverage. This was the final step in solving the problem.
The best team to drive this? The team(s) that created the data, of course! They best know what the cleanest representation of the data should be.
Agreeing on a uniform schema amongst downstream systems was still a joint effort though.
LinkedIn established a mandatory code review process between all involved teams - whenever schema code was changed, there would need to be LGTMs from stakeholders before the next production release8.
A side-effect of this was that it helped document the thousands of fields in their hundreds of schemas.
Summary
This was a very long-winded way of saying that:
data needs to be integrated between many systems
schemas play a very crucial role in this, make sure you define them well and establish good ownership
Kafka, with schemas, was literally invented to solve this problem at scale.
In the end, this proved very effective for LinkedIn. A single engineer was able to implement and maintain the process that does data loads for all topics with no incremental work or co-ordination needed as teams add new topics or change schemas.
Source: this 2012 paper and this blog.
Schema Driven Development Anyone?
One thing that surprised me while reading this paper was the emphasis on schemas.
I’ve been vocal before that I believe the lack of first-class schema support was Kafka’s biggest mistake.
The paper’s solution shares a lot similarities to Buf’s schema-driven development vision. Buf has been talking about universal schemas for the longest time, and built a diskless Kafka system that prioritizes schemas as a first-class citizen. I haven’t seen any other Kafka provider focus on schemas that much.
What surprised me precisely in this paper is that it, 13+ years ago, described a problem for which LinkedIn literally invented Kafka and auxiliary systems to solve, then took their time to write out the universal schema solution really well:
why am I hearing about this schema-centric vision a full decade later from a Protobuf/Kafka startup?
I’ve posted before on how Kafka lacks first-class schemas and how Buf seems to be the only one in the space beating the drum on their importance:
❌ Every valuable use-case requires schemas. You can’t use Kafka Connect to integrate data between upstream system A, Kafka and downstream system B without the existence of schemas — because chances are both systems A & B require some structure. Ditto for stream processing - you can’t do joins and aggregations on 1s and 0s.
❌ Every message has a schema - it’s either explicit and defined in a single place, or implicit and scattered throughout your application’s code.
❌ Fragmentation - absent of an “official” schema registry that ships with Kafka, we have dozens of options to choose from - Confluent’s Schema Registry, Karaspace, AWS Glue, Apicurio, Buf’s Schema Registry, etc.
❌ No Server-Side Validation - the Producer client is the only one who validates the schema prior to writing. There’s no way to defend against buggy (or malicious) clients, hence no way to enforce a uniform schema under all circumstances.
Again, I really commend Buf’s server-side validation. When you embrace the fundamental idea that messages must have schemas and enforce it on the server, a lot of things open up:
Native Iceberg integration - writing into an open table format becomes a trivial job of translating one schema language (e.g Avro or Protobuf) to another’s (Parquet’s)9
Semantic validation - ensuring message fields match a specific format (e.g email validation, age validation)
Filtering fields based on policies (RBAC) - certain sensitive fields ought to not be readable by certain groups.
Debugging - if a bad message somehow makes it in there (e.g configuration wasn’t right), the server can immediately pin-point it.
Filtering bad messages directly on the server - avoiding the need to have custom poison pill handling code (e.g send into a DLQ topic) in each consumer application.

poison pills in action. IYKYK

Schemaless Kafka
Lack of schemas continues to be my biggest gripe with Kafka.
The fact that LinkedIn treated schemas as first-class citizens all the way back in 2012 really has left me scratching my head…
They knew this was a major problem, yet never baked it into the product. Neither did Confluent after branching out of LinkedIn.
I’m uncertain how much of the schema decision was a business decision versus a technical one.
Back in the days, Confluent made their money off of their on-premise Confluent Platform package which priced things per node, hence a financial incentive existed to deploy more nodes (i.e. a schema registry cluster with three nodes for HA versus bundling it in the broker).
Perhaps there was investor pressure to preserve pricing optionality? Any business has to make money, and you can’t give away your most valuable features. It’s pretty common in the open-core business model to gate enterprise features behind paywalls.
Schema Registry is source-available though. In fact, it’s pretty much free to use unless you plan on selling it as a SaaS. But basic features like ACLs require a paid license. Something open-source Schema Registries like Karaspace offer for free. And hence my point on fragmentation in the space. It’s got to the point where we have to have proxies that enforce schemas10.
At the same time, there are some technical reasons why no-schema can be preferred:
Enforcement on the client scales easier, as no bottleneck exists in the broker.
Any state management on the broker could require extra resource usage (parsing schemas11, validating) and worse off — it could block the stream as it’d require additional locking. That’s contrary to the value prop of Kafka for slinging lots of bytes fast.
I believe it didn’t have to be an either-or decision today. Kafka could have shipped with first-class schema support built into topics - just an optional toggle.
And I don’t think performance would be hurt to the point of being unusable. Few people push Kafka to its true limits anyway - it’s frequently bottlenecked on network and storage. Not to mention that serialization overhead on CPUs has gone a long way since 2011 - the Java libraries improved, Java’s GC improved, JVM improved and CPU perf skyrocketed.
In hindsight, it’s clear that the schemaless wave (“it’s just byte arrays!”) was a fad that went away. We see which model won out in the SQL vs NoSQL wars - Postgres is not eating the world today by accident.12
I keep asking - why doesn’t Apache Kafka have schemas?
Additionally, if you enjoy this letter and its writing - support our growth by reposting this to your network in LinkedIn - https://www.linkedin.com/posts/stanislavkozlovski_why-was-apache-kafka-created-i-wrote-about-activity-7364651793995173889-BLhM. ✌️
Or on Twitter/X -
My understanding is this was all sort of user activity on the website. Sending a message to somebody, applying for a job, liking a post, reposting something, commenting under something, opening a profile. Basic features off the website work on this principle - e.g you get a notification of who “viewed your profile”. Less basic things too - the newsfeed adjusts to what you’ve been consuming; jobs get recommended to you based on what you’ve been applying to/viewing, etc.
I used to always confuse upstream and downstream together for whatever reason, so let me clarify: data has a source (where it comes from) and a destination (where it goes to). In this article, I use the following words interchange-ably: {Source, Upstream, Producer} and {Destination, Downstream, Sink, Consumer}
Probably the #1 problem in data engineering - schemas aren’t respected! They’re the contract between your systems, so naturally any unexpected changes there will break the pipeline. We, as an industry, need to treat this contract as something explicit (not implicit) and develop more tooling/automation around it.
Said more explicitly, if my schema database naively stores only one schema (e.g. a key-value pair of topic name to latest schema), I wouldn’t be able to deserialize old messages because I don’t know their exact schema! This is an important problem to solve for, because even if you store very little data (e.g 24hrs’ worth), there will always be a t=1h time point where you have 1 hours’ worth of the latest schema and 23 hours’ worth of the old schema. No consumer would be able to read everything within that window until the old data gets deleted. Hence - versioning of schemas and associating each message to a version to the rescue.
Hadoop tools like Hive and Pig would work with many, many files, but expected one fixed schema for all of them. If you change the schema, it’s expected to rewrite all your historical data with the new schema. In LinkedIn’s case, this was hundreds of TBs worth of data.
Nowadays these tools are pretty standard. `buf breaking` is another standard CLI tool that comes to mind with relation to checking compatibility for protobuf
Unstructured data — data that does not conform to a pre-defined model or schema. This type of thing was very popular during the NoSQL wave.
This is what the buzzword Schema Governance means. A set of rules/processes/tools to help you control how schemas are handled in data pipelines.
Funnily this is what initially got me thinking into why Kafka doesn’t support schemas as first-class citizens. I asked about it on Reddit here - https://www.reddit.com/r/apachekafka/comments/1h80if5/why_doesnt_kafka_have_firstclass_schema_support/.
I think Kroxylicious is super cool. But in an ideal world, we wouldn’t need a third-party proxy to enforce such a basic feature.
I don’t have actual data as to how much resource usage parsing would take. I tried figuring out how Bufstream does it (since they’re the only solution with server-side validation i.e parsing) and they seemed to have written their own protobuf parser that’s allegedly 10x faster. Maybe something like that is necessary to keep performance under check. Even if so - that parser is Apache-licensed so nothing would stop Kafka from adopting it.
Well, it didn’t literally go away - it just faded in significance. Postgres supports “NoSQL” like JSON arrays too now, and the general flexibility is welcomed. But it’s clear it’s not the default.
Thanks for writing this.
Its amazing to see what reasons actually propelled people to build something like Kafka that is used in so many different use cases today.